
CNN (Convolution Neural Network)
10 Feb 2019 | Deep_Learning HS
본 포스팅은 CNN에 대한 블로그와 부산 대학교 랩실의 강의 노트를 바탕으로 이뤄졌고, 예시 코드는 모두, 함께 공부하는 고동형 학우의 깃허브 의 코드를 인용하고 변형하여 사용하였습니다. 문제 시, 바로 내리겠습니다.
본 포스팅은 단순히 개인 공부 정리 용도이며, 저자는 배경 지식이 많이 부족한 이유로, 최선을 다하겠지만 분명히 완벽하지 않거나, 틀린 부분이 있을 수 있습니다. 계속해서 수정해나가도록 하겠습니다.
CNN
예시 코드와 CNN 알고리즘에 대한 공부는 자연어 처리에 맞춰 진행될 예정입니다.
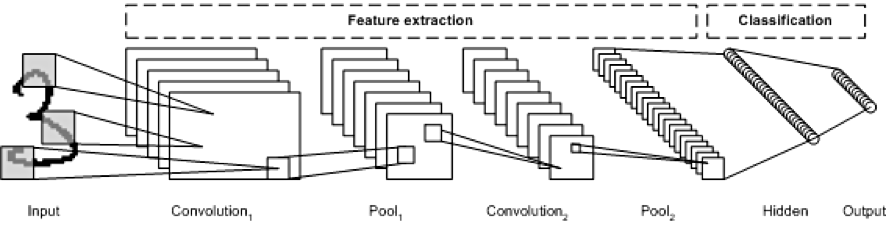
위의 사진은 숫자 필기체 이미지를 CNN을 통해 인식하는 전체 과정을 시각화한 이미지입니다. 기존의 Neural Network 와 비교되는 CNN의 특징은 여러 가지가 있지만, 자연어처리 분야에 접목시켜 생각해본다면, 다음과 같습니다.
- 공간 정보를 유지하면서 인접 텍스트와의 특징을 효과적으로 인식한다.
- 추출한 텍스트의 특징을 모으고 강화하는 pooling layer
- 필터를 공유 파라미터로 사용, 학습 파라미터의 수가 현격히 줄어든다.
즉, 텍스트를 인식할 때, fully connected layer 가 아닌, filter 단위로 인식하고 learning하기 때문에, 파라미터의 수가 줄어들고, 인접해있는 텍스트의 특징들을 개별이 아닌 공간적으로 인식한다는 것입니다.
또한, CNN 프로세스는 크게 두 가지로 나뉘어 생각할 수 있습니다. 위 사진을 기준으로,
- Input -> Convolution -> Pool -> .. Fully connected layer 이전까지
- 입력 데이터의 특징 추출 단계
- Fully connected layer -> Hidden -> softmax (끝까지)
- 분류 단계
자연어처리(Natural language processing)에 CNN이 사용되는 것으로, 시발점이 된 논문 에서 사용되는 이미지를 보면, 다음과 같습니다.

이미지에서 사용되는 cnn filter 와 자연어처리에서 사용되는 filter의 차이점을 알 수 있는 부분은
필터의 크기에서 알 수 있는데요. 이미지의 경우, N X N 의 픽셀 이미지에서 n X m 으로 다양한 필터의 shape 을 가질 수 있지만, nlp 에서 적용되는 필터의 크기는 n X N 의 필터에 대한 조건을 가지게 됩니다. 즉, 필터의 컬럼(column)의 길이는, 각 문장 또는 문서의 길이(scale)와 일치해야 한다는 것이죠.
지금부터는 CNN의 전체적인 프로세스를 입력 데이터가 텍스트라는 가정 아래 풀어보겠습니다.
Convolution
합성곱이라는 뜻으로, 쉽게 말하면, 벡터화된 입력 데이터에 필터를 갖다대어서 필터의 크기만큼, 합성곱을 하는 것입니다. 행렬 연산(Matrix Multiplication)과는 다르게, 합성곱은 매칭되는 인덱스끼리그 요소를 곱해주는 것을 의미합니다. 각각의 필터에 속한 각각의 인덱스에는 다른 가중치(weight)가 할당되어 있고, 이는 back-propagation 에 따라 최적화됩니다.
바로 위에서 보여지는 사진에서는 가장 왼쪽에 있는 사진의 입력 데이터(예시에서는 하나의 row가 한 단어를 의미하는 word vector이고 전체 행렬은 문장을 의미합니다.) 에 fractional scale 의 필터가 적용되어, 바로 오른쪽에서 scala 값으로 표현되는데, 이는 합성곱의 특징상, 매칭되는 인덱스끼리 곱해 그 값들을 합해주기 때문에, 0-dimension의 값이 나오게 되는 것입니다. 따라서, 두 번째 단계의 아래에 쓰여있는 Convolutional layer with multiple filter widths and feature maps의 의미는, 두 번째 프로세스에서 여러 개의 벡터들이 형성 되어 있는데, 차원으로 표시하면 (합성곱 횟수 X 1 X 필터 갯수) 와 같습니다. 이와 같이 필터의 종류에 따라서, 그 갯수만큼의 벡터들이 나오게 되는 것을 의미합니다.
Padding
데이터 전처리 과정에 포함되어 있는 프로세스로써, 이미지의 경우 이미지의 모서리 부분을 인식시켜주거나, 합성곱 연산의 횟수를 늘리는 데에 사용됩니다. 자연어처리의 경우 문장의 길이가 굉장히 다양하고, CNN에서는 이 길이를 일정하게 맞춰주어야 하기 때문에, 패딩을 실시합니다.
"저의 이름은 홍길동입니다."
"난 홍길동이야. <PADDING>" # 기존 문장의 길이가 더 짧기 때문에, 패딩을 통해 길이를 맞춰준다.
Sub-sampling(Pooling)
합성곱 벡터들을 받게 되면, 출력 데이터의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용됩니다.
가장 강한 특징만 채택하여 선택하는 방법인 max-pooling을 가장 일반적으로 사용합니다.
바로 위의 사진을 다시 한 번 참고하면, 두 번째 단계에서 합성곱에 따라 필터 종류만큼 벡터가 형성되었습니다. 그 후, 각각의 벡터에 대해 max-pooling 을 하게 되면, 하나의 벡터에서 단 하나의 값만 추출되어서, 세 번째 단계에서는 차원이 (필터 종류 X 1) 의 벡터로 차원이 축소됩니다.
pytorch example
다시 한 번 말씀드리지만,함께 공부하는 고동형 학우의 깃허브 의 코드를 인용하고 필요 시, 제가 변형하여 사용하였습니다. 데이터는 naver_movie_review_sentiment_classification 를 사용했습니다.
우선, 받아온 데이터를 scikit-learn 메소드를 통해 나눠줍니다.
X_train, X_test, y_train, y_test = \
train_test_split(data['token'],data['category'], test_size=0.2, random_state=42)
아래의 코드는 문장의 max_length 를 정해주고, 이를 충족하지 못하면, 패딩을 실시하고, 넘치면 max_length에 맞춰 잘라주는 코드입니다. tail은 패딩을 양쪽에 실시할지 뒤에만 실시할 지에 대한 옵션입니다.
def add_padding(before_token,tail=False,max_length=400) :
max_length = max_length
pad = '<PAD> '
for word in before_token :
if tail :
if len(word.split(" ")) < max_length :
num_pad = max_length - len(word.split(' '))
with_pad = word + ' '+ (num_pad - num_pad//2) * pad
yield with_pad.strip()
if len(word.split(" ")) < max_length :
num_pad = max_length - len(word.split(' '))
with_pad = num_pad//2 * pad + word + ' '+ (num_pad - num_pad//2) * pad
yield with_pad.strip()
else :
with_pad = ','.join(word.split(' ')[:max_length]).replace(',',' ')
yield with_pad
X_train = list(add_padding(X_train,tail=False))
X_test = list(add_padding(X_test,tail=False))
'<PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD>사업 행사 대출 보증 시행 산시 대신 줘도 손금 산입 세금 떠안 국내 건업 직접 제공 보증 대위변제 따른 상채 대손금 건설사 손금 산입 도록 개정안 국무 회의 최종 통과 이달 공포 시행 예정 건설사 괴롭힌 듣보잡 세금 규제 건설사 아파트 분양 사업 사업 따내 행사 사업 자금 대출 보증 관례 일반 행사(중략) 문제 심각 일깨우 제도 개선 필요 다는 주장 지속 제기 특히 개최 세제 실장 초청 재무 조찬 포럼 비롯 개최 건설 세제 정상 토론회 문제 개선 필요 제기 건설사 업계 전문가 목소리 토론회 기획 기사 정부 당국 전달 <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD>'
아래의 코드는, defaultdict를 통해, 각각의 단어들을 유니크하게 키와 값을 할당하는 코드입니다. 또한, 함수에 적용하기 전에 패딩 ‘' 이라는 키에 대해 0이라는 값을 매겨주기 위해 우선적으로 딕셔너리에 할당합니다.
# 단어에 대한 idx 부여
def convert_token_to_idx(token_ls):
for tokens in token_ls:
yield [token2idx[token] for token in tokens.split(' ')]
return
token2idx = defaultdict(lambda : len(token2idx)) # token과 index를 매칭시켜주는 딕셔너리
pad = token2idx['<PAD>'] # pytorch Variable로 변환하기 위해, 문장의 길이를 맞춰주기 위한 padding
X_train = list(convert_token_to_idx(X_train))
X_test = list(convert_token_to_idx(X_test))
idx2token = {val : key for key,val in token2idx.items()}
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 14, 19, 20, 21, 22, 23, 24, 25, 26, 27, 11, 28, 29, 30, 31, (중략) 174, 117, 128, 175, 176, 122, 124, 177, 165, 178, 179, 180, 181, 182, 183, 177, 184, 165, 185, 186, 73, 174, 117, 122, 14, 187, 129, 115, 186, 30, 188, 133, 189, 190, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
pytorch의 연산과정에 입력 데이터를 올려주기 위해 아래의 코드를 실행합니다. 아시다시피 X,y는 바뀌어야 하는 파라미터가 아니기 때문에, requires_grad 부분은 False로 처리합니다.
# torch Variable로 변환
def convert_to_variable(x, dtype=torch.long, requires_grad=False):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
return Variable(torch.tensor(x, dtype=dtype, device=device, requires_grad=requires_grad))
X_train = convert_to_variable(X_train)
X_test = convert_to_variable(X_test)
y_train = convert_to_variable(y_train)
y_test = convert_to_variable(y_test)
class CNN(nn.Module) :
def __init__(self,VOCAB_SIZE , EMBED_SIZE , HID_SIZE , DROPOUT ,
KERNEL_SIZE , NUM_FILTER , N_CLASS , TOKEN2IDX ) :
super(CNN, self).__init__()
self.vocab_size = VOCAB_SIZE
self.embed_size = EMBED_SIZE
self.hid_size = HID_SIZE
self.dropout = DROPOUT
self.kernel_size = KERNEL_SIZE
self.num_filter = NUM_FILTER
self.num_class = N_CLASS
self.token2idx = TOKEN2IDX
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.embedding = nn.Embedding(
num_embeddings = self.vocab_size,
embedding_dim = self.embed_size,
padding_idx = self.token2idx['<PAD>'])# token2idx 라는 딕셔너리에서 '<PAD>'는 학습에서 제외시킨다.
self.convs = nn.ModuleList([(nn.Conv2d(in_channels = 1,out_channels = self.num_filter,\
kernel_size = (kernel,self.embed_size))) for kernel in self.kernel_size])
# Modulelist 메소드를 통해, 여러개의 convolution filter 를 convs라는 변수에 객체로 할당한다.
self.fully_connect = nn.Sequential(
nn.Linear(self.num_filter * len(self.kernel_size),self.hid_size),nn.ReLU(),
nn.Dropout(self.dropout),nn.Linear(self.hid_size , self.num_class),
)
# torch.nn 모듈의 메소드 Sequential 은 pytorch pipeline을 지원해주는 메소드로써, 위에서 언급한 CNN의 두 번째 단계인 분류 단계를 실행하는 파이프라인을 fully_connect라는 변수에 할당해, 일종의 함수로 만든다.
def forward(self,x) :
if len(x.shape) == 1 :
x.unsqueeze_(0)
embed = self.embedding(x)
embed.unsqueeze_(1) # [batch_size, Non_dim , max_length , embedding_dim]
convolution = [conv(embed).squeeze(3) for conv in self.convs]
# nlp 에서 convolution 을 돌리면, feature_map 의 크기가 embedding dimension 과 같기 때문에, 1이 된다.
# embedding dimension 의 dimension index는 3이였기 때문에, 3 index squeeze 해준다.
# 또한 max_length 의 길이를 가졌던 2번째 인덱스가 kernel size 로 인해, 그 수가 변한다.
# [batch_size, num_filter, max_length -kernel_size +1]
pooled = [F.max_pool1d(conv,(conv.size(2))).squeeze(2) for conv in convolution]
# max_polling 은, 같은 kernel size 를 가지는, 동일한 filter에 대해 적용된다. ( 물론 실질적 format은 벡터이다.)
# 따라서 pooling 을 해줄때, 두 번째 파라미터로 conv.size(2) 를 해주는 것이다. 이에 따라, 벡터값이 max값만 추출,
# 스칼라가 된다.
# [batch_size, num_filter,1]
dropout = [F.dropout(pool,self.dropout) for pool in pooled]
# 두 번째 인자 dropout 은 확률값의 형태이며, epoch 가 바뀔 때마다, 은닉층의 뉴런을 dropout % 을 dropout 한다.
concatenate = torch.cat(dropout, dim = 1)
#concatenate 해서 NN을 돌려준다. 같은 kernel_size 가 같은 얘들끼리 concat 시킨다.
# [batch_size , num_filter * num_kernel]
logit = self.fully_connect(concatenate)
# NN layer 에 넣어주는 과정이다.
# concat 의 차원에 맞춰 linear layer 에 넣어주고,
#비선형성을 위해 relu activation function 에 넣어준 후, dropout 을 거쳐
# 마지막 값은 num_of_class 같의 벡터가 나온다.
# binary classfication 이면 길이가 2인 벡터
softmax = torch.log_softmax(logit,dim=1)
#마지막 값은 확률값의 형태로 출력
return softmax
optimizer 의 learning rate을 점진적으로 줄게 하기 위해서, 아래의 코드를 적용합니다.
def adjust_learning_rate(optimizer, epoch, init_lr=0.1, decay = 0.1 ,per_epoch=10):
"""Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
for param_group in optimizer.param_groups:
param_group['lr'] *= 1/(1 + decay)
return optimizer , float(param_group['lr'])
아래의 코드는 만든 CNN 객체를 트레이닝하는 코드입니다. optimizer 로 Adam 을 사용하였고, Negative log loss 를 사용하였습니다.
def train(model,X_train , X_test , y_train , y_test , epochs = 10, lr = 0.0001, batch_size = 200) :
early_stopping_cnt = 0
num_train_doc = X_train.size(0)
num_train_ls = np.arange(num_train_doc)
num_test_doc = X_test.size(0)
train_batch_size_ls = np.arange(0,num_train_doc,batch_size)
test_batch_size_ls = np.arange(0,num_test_doc,batch_size)
early_stopping_log_ls = []
optimizer = torch.optim.Adam(model.parameters(),lr)
criterion = nn.NLLLoss(reduction = 'sum')
for epoch in range(1,epochs+1) :
optimizer , lr_int = \
adjust_learning_rate(optimizer, epoch, init_lr=lr, decay = 0.1 ,per_epoch=10)
model.train()
random.shuffle(num_train_ls)
X_train[num_train_ls]
y_train[num_train_ls]
train_loss = 0
for idx in range(len(train_batch_size_ls)-1) :
if num_train_doc % 1000 ==0 : print('{} 번 째 데이터입니다.'.format(idx))
x_batch = X_train[train_batch_size_ls[idx] : train_batch_size_ls[idx+1]]
y_batch = y_train[train_batch_size_ls[idx] : train_batch_size_ls[idx+1]].long()
train_softmax = model(x_batch)
train_predict = train_softmax.argmax(dim=1)
train_acc = (train_predict == y_batch).sum().item() / batch_size
loss = criterion(train_softmax, y_batch)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Train epoch : %s, loss : %s, accuracy :%.3f, learning rate :%.3f'%(epoch, train_loss / batch_size, train_acc,lr_int))
print('=================================================================================================')
if (epoch) % 2 == 0:
model.eval()
n_correct = 0 # accuracy 계산을 위해 맞은 갯수 카운트
val_loss = 0
for idx in range(len(test_batch_size_ls)-1) :
x_batch = X_test[test_batch_size_ls[idx] : test_batch_size_ls[idx+1]]
y_batch = y_test[test_batch_size_ls[idx] : test_batch_size_ls[idx+1]].long()
test_softmax = model(x_batch)
test_predict = test_softmax.argmax(dim = 1)
loss = criterion(test_softmax, y_batch)
n_correct += (test_predict == y_batch).sum().item() #맞은 갯수
val_loss += loss.item()
acc = n_correct/num_test_doc
print('*************************************************************************************************')
print('*************************************************************************************************')
print('Val Epoch : %s, Val Loss : %.03f , Val Accuracy : %.03f'%(epoch, val_loss, acc))
print('*************************************************************************************************')
print('*************************************************************************************************')
# test_loss가 증가하면 lr decay
try:
if early_stopping_cnt[-1] > early_stopping_cnt[-2]:
early_stopping_cnt += 1
else:
early_stopping_cnt = 0
if early_stopping_cnt == 3:
print('오버피팅이 우려되어 학습을 중단합니다.')
break
except: pass
return
본 포스팅은 CNN에 대한 블로그와 부산 대학교 랩실의 강의 노트를 바탕으로 이뤄졌고, 예시 코드는 모두, 함께 공부하는 고동형 학우의 깃허브 의 코드를 인용하고 변형하여 사용하였습니다. 문제 시, 바로 내리겠습니다.
본 포스팅은 단순히 개인 공부 정리 용도이며, 저자는 배경 지식이 많이 부족한 이유로, 최선을 다하겠지만 분명히 완벽하지 않거나, 틀린 부분이 있을 수 있습니다. 계속해서 수정해나가도록 하겠습니다.
CNN
예시 코드와 CNN 알고리즘에 대한 공부는 자연어 처리에 맞춰 진행될 예정입니다.
위의 사진은 숫자 필기체 이미지를 CNN을 통해 인식하는 전체 과정을 시각화한 이미지입니다. 기존의 Neural Network 와 비교되는 CNN의 특징은 여러 가지가 있지만, 자연어처리 분야에 접목시켜 생각해본다면, 다음과 같습니다.
- 공간 정보를 유지하면서 인접 텍스트와의 특징을 효과적으로 인식한다.
- 추출한 텍스트의 특징을 모으고 강화하는 pooling layer
- 필터를 공유 파라미터로 사용, 학습 파라미터의 수가 현격히 줄어든다.
즉, 텍스트를 인식할 때, fully connected layer 가 아닌, filter 단위로 인식하고 learning하기 때문에, 파라미터의 수가 줄어들고, 인접해있는 텍스트의 특징들을 개별이 아닌 공간적으로 인식한다는 것입니다.
또한, CNN 프로세스는 크게 두 가지로 나뉘어 생각할 수 있습니다. 위 사진을 기준으로,
- Input -> Convolution -> Pool -> .. Fully connected layer 이전까지
- 입력 데이터의 특징 추출 단계
- Fully connected layer -> Hidden -> softmax (끝까지)
- 분류 단계
자연어처리(Natural language processing)에 CNN이 사용되는 것으로, 시발점이 된 논문 에서 사용되는 이미지를 보면, 다음과 같습니다.
이미지에서 사용되는 cnn filter 와 자연어처리에서 사용되는 filter의 차이점을 알 수 있는 부분은 필터의 크기에서 알 수 있는데요. 이미지의 경우, N X N 의 픽셀 이미지에서 n X m 으로 다양한 필터의 shape 을 가질 수 있지만, nlp 에서 적용되는 필터의 크기는 n X N 의 필터에 대한 조건을 가지게 됩니다. 즉, 필터의 컬럼(column)의 길이는, 각 문장 또는 문서의 길이(scale)와 일치해야 한다는 것이죠.
지금부터는 CNN의 전체적인 프로세스를 입력 데이터가 텍스트라는 가정 아래 풀어보겠습니다.
Convolution
합성곱이라는 뜻으로, 쉽게 말하면, 벡터화된 입력 데이터에 필터를 갖다대어서 필터의 크기만큼, 합성곱을 하는 것입니다. 행렬 연산(Matrix Multiplication)과는 다르게, 합성곱은 매칭되는 인덱스끼리그 요소를 곱해주는 것을 의미합니다. 각각의 필터에 속한 각각의 인덱스에는 다른 가중치(weight)가 할당되어 있고, 이는 back-propagation 에 따라 최적화됩니다.
바로 위에서 보여지는 사진에서는 가장 왼쪽에 있는 사진의 입력 데이터(예시에서는 하나의 row가 한 단어를 의미하는 word vector이고 전체 행렬은 문장을 의미합니다.) 에 fractional scale 의 필터가 적용되어, 바로 오른쪽에서 scala 값으로 표현되는데, 이는 합성곱의 특징상, 매칭되는 인덱스끼리 곱해 그 값들을 합해주기 때문에, 0-dimension의 값이 나오게 되는 것입니다. 따라서, 두 번째 단계의 아래에 쓰여있는 Convolutional layer with multiple filter widths and feature maps의 의미는, 두 번째 프로세스에서 여러 개의 벡터들이 형성 되어 있는데, 차원으로 표시하면 (합성곱 횟수 X 1 X 필터 갯수) 와 같습니다. 이와 같이 필터의 종류에 따라서, 그 갯수만큼의 벡터들이 나오게 되는 것을 의미합니다.
Padding
데이터 전처리 과정에 포함되어 있는 프로세스로써, 이미지의 경우 이미지의 모서리 부분을 인식시켜주거나, 합성곱 연산의 횟수를 늘리는 데에 사용됩니다. 자연어처리의 경우 문장의 길이가 굉장히 다양하고, CNN에서는 이 길이를 일정하게 맞춰주어야 하기 때문에, 패딩을 실시합니다.
"저의 이름은 홍길동입니다."
"난 홍길동이야. <PADDING>" # 기존 문장의 길이가 더 짧기 때문에, 패딩을 통해 길이를 맞춰준다.
Sub-sampling(Pooling)
합성곱 벡터들을 받게 되면, 출력 데이터의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용됩니다. 가장 강한 특징만 채택하여 선택하는 방법인 max-pooling을 가장 일반적으로 사용합니다. 바로 위의 사진을 다시 한 번 참고하면, 두 번째 단계에서 합성곱에 따라 필터 종류만큼 벡터가 형성되었습니다. 그 후, 각각의 벡터에 대해 max-pooling 을 하게 되면, 하나의 벡터에서 단 하나의 값만 추출되어서, 세 번째 단계에서는 차원이 (필터 종류 X 1) 의 벡터로 차원이 축소됩니다.
pytorch example
다시 한 번 말씀드리지만,함께 공부하는 고동형 학우의 깃허브 의 코드를 인용하고 필요 시, 제가 변형하여 사용하였습니다. 데이터는 naver_movie_review_sentiment_classification 를 사용했습니다.
우선, 받아온 데이터를 scikit-learn 메소드를 통해 나눠줍니다.
X_train, X_test, y_train, y_test = \
train_test_split(data['token'],data['category'], test_size=0.2, random_state=42)
아래의 코드는 문장의 max_length 를 정해주고, 이를 충족하지 못하면, 패딩을 실시하고, 넘치면 max_length에 맞춰 잘라주는 코드입니다. tail은 패딩을 양쪽에 실시할지 뒤에만 실시할 지에 대한 옵션입니다.
def add_padding(before_token,tail=False,max_length=400) :
max_length = max_length
pad = '<PAD> '
for word in before_token :
if tail :
if len(word.split(" ")) < max_length :
num_pad = max_length - len(word.split(' '))
with_pad = word + ' '+ (num_pad - num_pad//2) * pad
yield with_pad.strip()
if len(word.split(" ")) < max_length :
num_pad = max_length - len(word.split(' '))
with_pad = num_pad//2 * pad + word + ' '+ (num_pad - num_pad//2) * pad
yield with_pad.strip()
else :
with_pad = ','.join(word.split(' ')[:max_length]).replace(',',' ')
yield with_pad
X_train = list(add_padding(X_train,tail=False))
X_test = list(add_padding(X_test,tail=False))
'<PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD>사업 행사 대출 보증 시행 산시 대신 줘도 손금 산입 세금 떠안 국내 건업 직접 제공 보증 대위변제 따른 상채 대손금 건설사 손금 산입 도록 개정안 국무 회의 최종 통과 이달 공포 시행 예정 건설사 괴롭힌 듣보잡 세금 규제 건설사 아파트 분양 사업 사업 따내 행사 사업 자금 대출 보증 관례 일반 행사(중략) 문제 심각 일깨우 제도 개선 필요 다는 주장 지속 제기 특히 개최 세제 실장 초청 재무 조찬 포럼 비롯 개최 건설 세제 정상 토론회 문제 개선 필요 제기 건설사 업계 전문가 목소리 토론회 기획 기사 정부 당국 전달 <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD> <PAD>'
아래의 코드는, defaultdict를 통해, 각각의 단어들을 유니크하게 키와 값을 할당하는 코드입니다. 또한, 함수에 적용하기 전에 패딩 ‘
# 단어에 대한 idx 부여
def convert_token_to_idx(token_ls):
for tokens in token_ls:
yield [token2idx[token] for token in tokens.split(' ')]
return
token2idx = defaultdict(lambda : len(token2idx)) # token과 index를 매칭시켜주는 딕셔너리
pad = token2idx['<PAD>'] # pytorch Variable로 변환하기 위해, 문장의 길이를 맞춰주기 위한 padding
X_train = list(convert_token_to_idx(X_train))
X_test = list(convert_token_to_idx(X_test))
idx2token = {val : key for key,val in token2idx.items()}
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 14, 19, 20, 21, 22, 23, 24, 25, 26, 27, 11, 28, 29, 30, 31, (중략) 174, 117, 128, 175, 176, 122, 124, 177, 165, 178, 179, 180, 181, 182, 183, 177, 184, 165, 185, 186, 73, 174, 117, 122, 14, 187, 129, 115, 186, 30, 188, 133, 189, 190, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
pytorch의 연산과정에 입력 데이터를 올려주기 위해 아래의 코드를 실행합니다. 아시다시피 X,y는 바뀌어야 하는 파라미터가 아니기 때문에, requires_grad 부분은 False로 처리합니다.
# torch Variable로 변환
def convert_to_variable(x, dtype=torch.long, requires_grad=False):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
return Variable(torch.tensor(x, dtype=dtype, device=device, requires_grad=requires_grad))
X_train = convert_to_variable(X_train)
X_test = convert_to_variable(X_test)
y_train = convert_to_variable(y_train)
y_test = convert_to_variable(y_test)
class CNN(nn.Module) :
def __init__(self,VOCAB_SIZE , EMBED_SIZE , HID_SIZE , DROPOUT ,
KERNEL_SIZE , NUM_FILTER , N_CLASS , TOKEN2IDX ) :
super(CNN, self).__init__()
self.vocab_size = VOCAB_SIZE
self.embed_size = EMBED_SIZE
self.hid_size = HID_SIZE
self.dropout = DROPOUT
self.kernel_size = KERNEL_SIZE
self.num_filter = NUM_FILTER
self.num_class = N_CLASS
self.token2idx = TOKEN2IDX
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.embedding = nn.Embedding(
num_embeddings = self.vocab_size,
embedding_dim = self.embed_size,
padding_idx = self.token2idx['<PAD>'])# token2idx 라는 딕셔너리에서 '<PAD>'는 학습에서 제외시킨다.
self.convs = nn.ModuleList([(nn.Conv2d(in_channels = 1,out_channels = self.num_filter,\
kernel_size = (kernel,self.embed_size))) for kernel in self.kernel_size])
# Modulelist 메소드를 통해, 여러개의 convolution filter 를 convs라는 변수에 객체로 할당한다.
self.fully_connect = nn.Sequential(
nn.Linear(self.num_filter * len(self.kernel_size),self.hid_size),nn.ReLU(),
nn.Dropout(self.dropout),nn.Linear(self.hid_size , self.num_class),
)
# torch.nn 모듈의 메소드 Sequential 은 pytorch pipeline을 지원해주는 메소드로써, 위에서 언급한 CNN의 두 번째 단계인 분류 단계를 실행하는 파이프라인을 fully_connect라는 변수에 할당해, 일종의 함수로 만든다.
def forward(self,x) :
if len(x.shape) == 1 :
x.unsqueeze_(0)
embed = self.embedding(x)
embed.unsqueeze_(1) # [batch_size, Non_dim , max_length , embedding_dim]
convolution = [conv(embed).squeeze(3) for conv in self.convs]
# nlp 에서 convolution 을 돌리면, feature_map 의 크기가 embedding dimension 과 같기 때문에, 1이 된다.
# embedding dimension 의 dimension index는 3이였기 때문에, 3 index squeeze 해준다.
# 또한 max_length 의 길이를 가졌던 2번째 인덱스가 kernel size 로 인해, 그 수가 변한다.
# [batch_size, num_filter, max_length -kernel_size +1]
pooled = [F.max_pool1d(conv,(conv.size(2))).squeeze(2) for conv in convolution]
# max_polling 은, 같은 kernel size 를 가지는, 동일한 filter에 대해 적용된다. ( 물론 실질적 format은 벡터이다.)
# 따라서 pooling 을 해줄때, 두 번째 파라미터로 conv.size(2) 를 해주는 것이다. 이에 따라, 벡터값이 max값만 추출,
# 스칼라가 된다.
# [batch_size, num_filter,1]
dropout = [F.dropout(pool,self.dropout) for pool in pooled]
# 두 번째 인자 dropout 은 확률값의 형태이며, epoch 가 바뀔 때마다, 은닉층의 뉴런을 dropout % 을 dropout 한다.
concatenate = torch.cat(dropout, dim = 1)
#concatenate 해서 NN을 돌려준다. 같은 kernel_size 가 같은 얘들끼리 concat 시킨다.
# [batch_size , num_filter * num_kernel]
logit = self.fully_connect(concatenate)
# NN layer 에 넣어주는 과정이다.
# concat 의 차원에 맞춰 linear layer 에 넣어주고,
#비선형성을 위해 relu activation function 에 넣어준 후, dropout 을 거쳐
# 마지막 값은 num_of_class 같의 벡터가 나온다.
# binary classfication 이면 길이가 2인 벡터
softmax = torch.log_softmax(logit,dim=1)
#마지막 값은 확률값의 형태로 출력
return softmax
optimizer 의 learning rate을 점진적으로 줄게 하기 위해서, 아래의 코드를 적용합니다.
def adjust_learning_rate(optimizer, epoch, init_lr=0.1, decay = 0.1 ,per_epoch=10):
"""Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
for param_group in optimizer.param_groups:
param_group['lr'] *= 1/(1 + decay)
return optimizer , float(param_group['lr'])
아래의 코드는 만든 CNN 객체를 트레이닝하는 코드입니다. optimizer 로 Adam 을 사용하였고, Negative log loss 를 사용하였습니다.
def train(model,X_train , X_test , y_train , y_test , epochs = 10, lr = 0.0001, batch_size = 200) :
early_stopping_cnt = 0
num_train_doc = X_train.size(0)
num_train_ls = np.arange(num_train_doc)
num_test_doc = X_test.size(0)
train_batch_size_ls = np.arange(0,num_train_doc,batch_size)
test_batch_size_ls = np.arange(0,num_test_doc,batch_size)
early_stopping_log_ls = []
optimizer = torch.optim.Adam(model.parameters(),lr)
criterion = nn.NLLLoss(reduction = 'sum')
for epoch in range(1,epochs+1) :
optimizer , lr_int = \
adjust_learning_rate(optimizer, epoch, init_lr=lr, decay = 0.1 ,per_epoch=10)
model.train()
random.shuffle(num_train_ls)
X_train[num_train_ls]
y_train[num_train_ls]
train_loss = 0
for idx in range(len(train_batch_size_ls)-1) :
if num_train_doc % 1000 ==0 : print('{} 번 째 데이터입니다.'.format(idx))
x_batch = X_train[train_batch_size_ls[idx] : train_batch_size_ls[idx+1]]
y_batch = y_train[train_batch_size_ls[idx] : train_batch_size_ls[idx+1]].long()
train_softmax = model(x_batch)
train_predict = train_softmax.argmax(dim=1)
train_acc = (train_predict == y_batch).sum().item() / batch_size
loss = criterion(train_softmax, y_batch)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Train epoch : %s, loss : %s, accuracy :%.3f, learning rate :%.3f'%(epoch, train_loss / batch_size, train_acc,lr_int))
print('=================================================================================================')
if (epoch) % 2 == 0:
model.eval()
n_correct = 0 # accuracy 계산을 위해 맞은 갯수 카운트
val_loss = 0
for idx in range(len(test_batch_size_ls)-1) :
x_batch = X_test[test_batch_size_ls[idx] : test_batch_size_ls[idx+1]]
y_batch = y_test[test_batch_size_ls[idx] : test_batch_size_ls[idx+1]].long()
test_softmax = model(x_batch)
test_predict = test_softmax.argmax(dim = 1)
loss = criterion(test_softmax, y_batch)
n_correct += (test_predict == y_batch).sum().item() #맞은 갯수
val_loss += loss.item()
acc = n_correct/num_test_doc
print('*************************************************************************************************')
print('*************************************************************************************************')
print('Val Epoch : %s, Val Loss : %.03f , Val Accuracy : %.03f'%(epoch, val_loss, acc))
print('*************************************************************************************************')
print('*************************************************************************************************')
# test_loss가 증가하면 lr decay
try:
if early_stopping_cnt[-1] > early_stopping_cnt[-2]:
early_stopping_cnt += 1
else:
early_stopping_cnt = 0
if early_stopping_cnt == 3:
print('오버피팅이 우려되어 학습을 중단합니다.')
break
except: pass
return
Comments