
Character-Aware Neural Language Models
16 Apr 2019 | NLP_paper HS
Convolutional Neural Network for sentence classification 에 이은 Yoon Kim 님의 2015년도 논문, “Character-Aware Neural Language Models” 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstract
문자(character) 레벨의 인풋값을 가지는 간단한 인공 신경망 기반 언어 모델을 제시한다. 예측은 여전히 단어 레벨에서 이뤄진다. 단어에는 CNN과 highway network가 적용되고, output은 단어 레벨을 띄며, LSTM 언어모델에 들어가게 된다. 결과는 많은 언어에서 문자 레벨이 언어 모델에 있어서 충분한 성능을 보임을 보였고, 의미론과 직교적(orthographic) 정보를 담고 있음을 알 수 있었다.
Introduction
전통적 언어 모델은 아래의 수식과 같은 조건부 확률, 즉 n-gram 확률을 예측함으로써
언어 모델의 과업를 해결하려 했지만, 데이터의 sparsity 문제로 인해서, 예측 성능이 좋지 못했다. 이후 인공신경망 언어 모델의 발전으로, sparsity 이슈를 벡터의 파라미터화로 해결하면서, 벡터에 의미론적 특징을 잡고, 단어를 벡터 공간에 투영함에 따른, 유사도 또한 계산할 수 있었다. ($word2vec$ 이전에는 Latent Semantic Analysis과 같은 방법론으로 차원을 줄여 임베딩하였다.)
NLM(인공신경망 언어 모델)이 빈도수 기반의 n-gram을 능가하는 성능을 가졌다고 하지만, 부가적 정보(subword information)을 잡아내는 것에는 취약하였다. 예로 들어서, $good,bad$ 가 유사한 위치에 존재하고, 근접한 단어가 유사하기 때문에, 벡터 공간 내에 유사하게 자리 잡고 있는 것과 마찬가지 예이다. 희소한 단어의 임베딩 또한, 높은 perplexity를(모델을 빠르게 평가하는 방법, 작을 수록 좋습니다.) 가져오는 결과를 낳았다.
해당 연구에서는, 문자 단위의 인풋을 CNN과 함께 사용하고, 아웃풋은 LSTM을 적용함에 따라, 언어모델에 subword information을 포착하려한다. 정리하자면, 우리 모델의 contribution은 아래와 같다.
- 영어에서, 현재 SOTA인 Penn Treebak과 60% 정도의 파라미터 수를 가진 상태에서 유사한 성능을 보였다.
- 형태소가 다양한 언어(체코, 러시아어 etc)에서 강점을 보였다.
Model
기존의 NLM 모델은 인풋값으로 단어 임베딩을 가지는 것에 반해, 우리의 모델은 single-layer 문자 레벨 CNN의 아웃풋을 max-over-time pooling한 것을 인풋값으로 가지게 된다.
-
Recurrent Neural Network
LSTM 을 사용한다는 내용입니다.
-
Recurrent Neural Network Language Model
$V$를 단어의 어휘에 대한 고정된 크기라고 하자. 언어 모델은 $t+1$시점의 단어 $w_{t+1}$에 대한 분포를 형성한다. (이 때, 분포의 집단의 $V$에 포함됩니다. 즉, softmax 값의 분모(denominator) 부분의 사이즈를 정하게 됩니다.)
위의 수식은 은 CharCNN 을 통과한 후에, character level이 word level 로 매핑된 후의 output입니다.
우리의 모델은 기존의 NLM 모델에서 사용하는 임베딩 벡터(위의 수식)를 softmax 를 취한 hidden state으로 인풋을 사용하게 된다. 우리는 이러한 인풋을 기반으로 Negative log likelihood를 최소화하는 방향으로 모델을 학습시킨다.

- Character-level Convolutional Neural Network
해당 섹션은 단어가 CNN에 통과하는 과정을 설명(describe)합니다.
$C$를 문자의 어휘 셋이라고 하자. $d$는 문자의 임베딩 차원이라고 하면, $Q ∈ R^{d*|C|}$의 $Q$는 단어의 임베딩 행렬이 된다. 따라서, 단어(word)가 $l$의 길이를 지녔다고 하면, $[c_{1},c_{2},c_{3},..,c_{l}]$가 된다.
아래의 식은, filter 사이즈가(width라고 표현합니다.) $w$라고 했을 때, stride를 $w-1$으로 했을 때, CNN을 거치고 나온 벡터의 차원이다.
아래의 식은, max-over-time-pooling을 하는 수식이다.
우리는 하나의 필터가 하나의 특징(feature)을 잡아낸다고 표현하였다. 우리의 CharCNN 모델은 여러개의 필터를 width를 변화시키며 적용하며, 단어 하나를 $k$로 표현하고, 사용한 필터의 갯수가 $h$였을 때, $[y_{1}^{k},y_{2}^{k}..,y_{h}^{k}]$ 로 표현할 수 있겠다.
- Highway Network
우리는 단어 임베딩 $x^{k}$을 CharCNN을 통해, $y^{k}$로 만들어 LSTM에 적용하게 된다. 이 상태에서 그대로 LSTM에 넣어도 좋은 성능을 보이지만, high network를 적용했을 때, 성능 향상을 보였다. 아래의 수식은 LSTM의 memory cells과 유사하다. 우리는 $t$를 $trasform$ gate이라 칭하고, $(1-t)$를 $carry$ gate라고 부른다. 해당 네트워크는 깊은 네트워크의 학습에서 중요한 부분의 차원을 선별적으로(adaptively) 끌고가 $input \rightarrow output$하는 과정이라 할 수 있다.

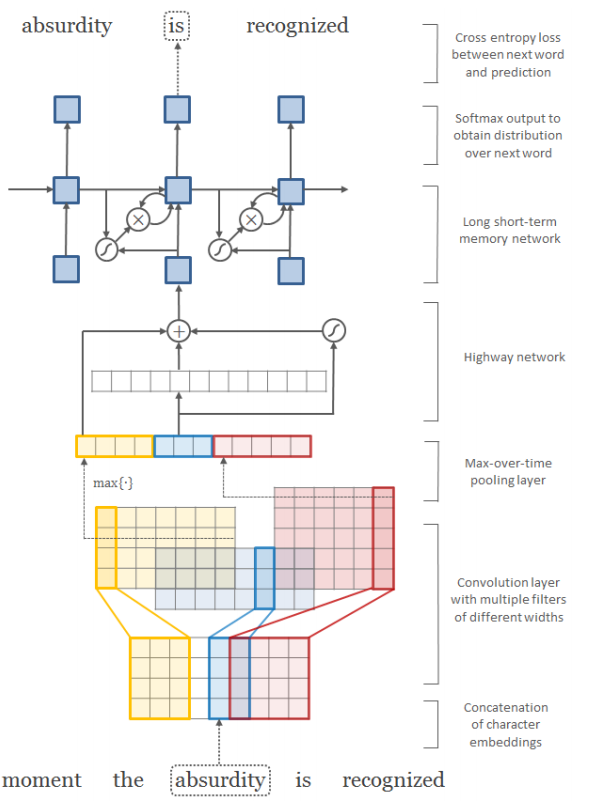
- Overall Networks
Optimization

- loss function : stochastic gradient descent
- batch size : 100
- Gradients are averaged over each batch
- 25 epochs on non-Arabic and 30 epochs on Arabic data
- parameter initialize : [-0.05,0.05]
- dropout : 0.5(LSTM input-to-hidden layers)
- norm of the gradients to be below 5
Results

Convolutional Neural Network for sentence classification 에 이은 Yoon Kim 님의 2015년도 논문, “Character-Aware Neural Language Models” 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstract
문자(character) 레벨의 인풋값을 가지는 간단한 인공 신경망 기반 언어 모델을 제시한다. 예측은 여전히 단어 레벨에서 이뤄진다. 단어에는 CNN과 highway network가 적용되고, output은 단어 레벨을 띄며, LSTM 언어모델에 들어가게 된다. 결과는 많은 언어에서 문자 레벨이 언어 모델에 있어서 충분한 성능을 보임을 보였고, 의미론과 직교적(orthographic) 정보를 담고 있음을 알 수 있었다.
Introduction
전통적 언어 모델은 아래의 수식과 같은 조건부 확률, 즉 n-gram 확률을 예측함으로써 언어 모델의 과업를 해결하려 했지만, 데이터의 sparsity 문제로 인해서, 예측 성능이 좋지 못했다. 이후 인공신경망 언어 모델의 발전으로, sparsity 이슈를 벡터의 파라미터화로 해결하면서, 벡터에 의미론적 특징을 잡고, 단어를 벡터 공간에 투영함에 따른, 유사도 또한 계산할 수 있었다. ($word2vec$ 이전에는 Latent Semantic Analysis과 같은 방법론으로 차원을 줄여 임베딩하였다.)
NLM(인공신경망 언어 모델)이 빈도수 기반의 n-gram을 능가하는 성능을 가졌다고 하지만, 부가적 정보(subword information)을 잡아내는 것에는 취약하였다. 예로 들어서, $good,bad$ 가 유사한 위치에 존재하고, 근접한 단어가 유사하기 때문에, 벡터 공간 내에 유사하게 자리 잡고 있는 것과 마찬가지 예이다. 희소한 단어의 임베딩 또한, 높은 perplexity를(모델을 빠르게 평가하는 방법, 작을 수록 좋습니다.) 가져오는 결과를 낳았다.
해당 연구에서는, 문자 단위의 인풋을 CNN과 함께 사용하고, 아웃풋은 LSTM을 적용함에 따라, 언어모델에 subword information을 포착하려한다. 정리하자면, 우리 모델의 contribution은 아래와 같다.
- 영어에서, 현재 SOTA인 Penn Treebak과 60% 정도의 파라미터 수를 가진 상태에서 유사한 성능을 보였다.
- 형태소가 다양한 언어(체코, 러시아어 etc)에서 강점을 보였다.
Model
기존의 NLM 모델은 인풋값으로 단어 임베딩을 가지는 것에 반해, 우리의 모델은 single-layer 문자 레벨 CNN의 아웃풋을 max-over-time pooling한 것을 인풋값으로 가지게 된다.
-
Recurrent Neural Network LSTM 을 사용한다는 내용입니다.
-
Recurrent Neural Network Language Model
$V$를 단어의 어휘에 대한 고정된 크기라고 하자. 언어 모델은 $t+1$시점의 단어 $w_{t+1}$에 대한 분포를 형성한다. (이 때, 분포의 집단의 $V$에 포함됩니다. 즉, softmax 값의 분모(denominator) 부분의 사이즈를 정하게 됩니다.)
위의 수식은 은 CharCNN 을 통과한 후에, character level이 word level 로 매핑된 후의 output입니다.
우리의 모델은 기존의 NLM 모델에서 사용하는 임베딩 벡터(위의 수식)를 softmax 를 취한 hidden state으로 인풋을 사용하게 된다. 우리는 이러한 인풋을 기반으로 Negative log likelihood를 최소화하는 방향으로 모델을 학습시킨다.
- Character-level Convolutional Neural Network
해당 섹션은 단어가 CNN에 통과하는 과정을 설명(describe)합니다. $C$를 문자의 어휘 셋이라고 하자. $d$는 문자의 임베딩 차원이라고 하면, $Q ∈ R^{d*|C|}$의 $Q$는 단어의 임베딩 행렬이 된다. 따라서, 단어(word)가 $l$의 길이를 지녔다고 하면, $[c_{1},c_{2},c_{3},..,c_{l}]$가 된다.
아래의 식은, filter 사이즈가(width라고 표현합니다.) $w$라고 했을 때, stride를 $w-1$으로 했을 때, CNN을 거치고 나온 벡터의 차원이다.
아래의 식은, max-over-time-pooling을 하는 수식이다.
우리는 하나의 필터가 하나의 특징(feature)을 잡아낸다고 표현하였다. 우리의 CharCNN 모델은 여러개의 필터를 width를 변화시키며 적용하며, 단어 하나를 $k$로 표현하고, 사용한 필터의 갯수가 $h$였을 때, $[y_{1}^{k},y_{2}^{k}..,y_{h}^{k}]$ 로 표현할 수 있겠다.
- Highway Network
우리는 단어 임베딩 $x^{k}$을 CharCNN을 통해, $y^{k}$로 만들어 LSTM에 적용하게 된다. 이 상태에서 그대로 LSTM에 넣어도 좋은 성능을 보이지만, high network를 적용했을 때, 성능 향상을 보였다. 아래의 수식은 LSTM의 memory cells과 유사하다. 우리는 $t$를 $trasform$ gate이라 칭하고, $(1-t)$를 $carry$ gate라고 부른다. 해당 네트워크는 깊은 네트워크의 학습에서 중요한 부분의 차원을 선별적으로(adaptively) 끌고가 $input \rightarrow output$하는 과정이라 할 수 있다.
- Overall Networks
Optimization
- loss function : stochastic gradient descent
- batch size : 100
- Gradients are averaged over each batch
- 25 epochs on non-Arabic and 30 epochs on Arabic data
- parameter initialize : [-0.05,0.05]
- dropout : 0.5(LSTM input-to-hidden layers)
- norm of the gradients to be below 5
Results
Comments