
Effective Approaches to Attention-based Neural Machine Translation
08 Apr 2019 | NLP_paper HS
Attention 논문에 이어서, 어탠션 메커니즘을 효율적으로 활용하는 구글에서 나온 논문 Neural Machine Effective Approaches to Attention-based Neural Machine Translation 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstact
어탠션 메카니즘은 source sentence의 특정 시퀀스에 집중시켜, 기계 번역의 성능을 향상시키는 데에 기여했다. 해당 논문은 효율적 어탠션 메카니즘을 두 가지 방식으로 제안 및 실험한다. 첫 번째는 global approach로, 모든 source sentence에 대해 어탠션을 적용한다. 두 번째로는 local approach로 source 단어들의 일부에 어탠션을 집중시킨다. local attention을 적용함에 따라, 어탠션이 적용되지 않은 방법보다 5.0 BLEU 만큼의 성능 향상이 있는 것을 보였다.
Introduction
기존의 RNN Encoder-Decoder 모델은 Sequence to Sequence의 기계학습을 가능케 만들었지만, 장거리 의존성을 잡아내기엔 무리가 있었다. 이어서 어탠션 메카니즘이 등장하였고, 자연어처리뿐만 아니라 많은 분야에서 해당 방법론이 사용되었다. 하지만, 이러한 어탠션 메카니즘을 어떻게 사용할 지에 대한 논의는 이뤄지지 않은 실정이다.
해당 논문에서 두 가지의 attention-based models 을 소개한다. source words에 대해 모두 어탠션을 적용하는 global approach와 한 번에 source words의 일부에 어탠션을 적용하는 local approach이다.
global approach는 2015년도의 Bahdanau 의 논문 형태와 유사하지만, 더욱 연산적으로 간단하다. local approach의 경우에는 hard attention 과 soft attention의 조합으로 나오며, 연산적으로 훨씬 간단하고 효율적이다.
Neural Machine Translation
인공신경망을 이용한 기계번역은 아래의 식을 최대화하는 방향으로 학습된다.
NMT에서 Encoder-Decoder 아키텍처를 쌓을 때, RNN 기반의 네트워크를 사용하는 것은 자연스러운 선택이였으며, 그동안 진행되오던 논문들은 Encoder가 Decoder에서 건네어 주는, source sentence에 대한 표상(representation)의 차이로 나뉘어졌다.
- Kalchbrenner and Blunsom (2013) 의 경우에는 decoder는 RNN 베이스를 사용하였고, Encoder에서 source sentence 표상을 CNN 모델로 진행하였다.
- Sutskever et al. (2014)dml 경우 multilayer_LSTM 의 hidden unit을 stack(concat) 사용하였다.
- Cho et al. (2014), Bahdanau et al. (2015), and Jean et al. (2015) 에서는 LSTM과 유사하지만, 연산의 간편성을 가지고 나온 GRU 모델을 아키텍처로 사용, 해당 모델의 hidden unit을 사용하였다.
위의 두 식을 순서대로 해석하면, 첫 번째는 Vanila RNN 의 update식을 의미한다. 두 번째는, Vanila RNN의 hidden units 이 어떻게 학습되는지에 관한 수식이다. $s$는 source sentence 의 word를 의미한다.
해당 연구에서는, Sutskever et al., 2014; Luong et al., 2015 의 연구에 따라서, LSTM을 여러 겹 쌓은 모델을 사용한다.
Attention-based Models
해당 연구에서 사용하는 Attention mechanism의 적용 방법은 global, local approach 모두 아래와 같은 형태로 동일하다.
위의 식을 차례로 설명하면, Encoder의 stacked LSTM의 가장 상단의 hidden state $h_{t}$와 context vector $c_{t}$를 concatenate한 후에, tanh 함수를 씌워준 형태이다. 즉, context vector와 hidden state를 쌓아준 후에, RNN 에 학습시켜 새로운 hidden units을 얻는 형태이다. 두 번째로는, 이렇게 update된 hidden unit에 따라, ouput의 분포를 반환하는 것을 의미한다.
Global Attention
Global attentional model의 아이디어는 인코더의 모든 hidden state들을 context vector를 만들 때 고려한다는 것이다. 이에 따라, context vector의 길이는 source sentence에 의존적이고, 가변 길이의 벡터가 된다.
$h_{t}$는 디코더의 hidden unit으로, 인코더에 있는 source words간의 attention energy를 기반으로 softmax를 취해주어, 계산해준다.
위와 같이 계산되는 score는 content-based 함수라고 불리며, 위와 같이 3 가지 선택사항이 존재한다..
기존의 논문들은 바로 위의 식과 같은 형태로 attention이 적용된 context vector를 만들었는데, 즉 attention weight가 도출되면 이를 context vector와 곱해 가중합을 취해주는 꼴이였다. 이를 local-based 함수라고 부른다.

우리들의 global approach 는 to Bahdanau et al., 2015 와 유사하지만, 몇 가지 다른 점들이 존재한다. 첫 번째로 이전 논문이 Encoder에서 Bi-directional LSTM 을 사용해, stacked hidden unit을 보냈지만, 우리는 Encoder Decoder모두 최상단에 있는 hidden unit만 사용한다. 두 번째로 우리들의 연산 경로가 더 간단하다는 것이다. 이전의 논문에서는 이전 시점의 hidden unit $h_{t-1}$에서 다음 시점 $h_{t}$를 제시하였지만, 해당 논문에서는 동일 시점의 target hidden state를 source hidden state 와 함께 concat해주고, context weights 를 적용해주기 때문이다. 마지막으로, 위에서 보였던, 3가지 방식을 우리는 모두 적용하였지만, 이전 논문은 3번째 방법만 제시하였다.
Local Attention
 global approach는 source sentence의 모든 스텝에 어탠션 메커니즘을 적용하기 때문에, 긴 문장에 대해서 비효율적인 연산을 진행해야 한다는 단점이 있다. 이에 따라서, source sentnece의 부분적인 스텝에만 어탠션을 적용하는 local approach를 제안한다. local approach는 source sentence의 window를 통한 부분적인 context에 선택적으로 집중할 수 있고, 해당 부분은 변화가 가능하다. context vector는 집중하는 윈두우 사이즈만큼의 $[p_{t} - D, p_{t} + D]$ 부분 내에서 계산 및 가중치가 계산되고, $D$는 경험적으로 선택된다. 우리는 해당 모델의 두 가지 사안을 고려하였다.
global approach는 source sentence의 모든 스텝에 어탠션 메커니즘을 적용하기 때문에, 긴 문장에 대해서 비효율적인 연산을 진행해야 한다는 단점이 있다. 이에 따라서, source sentnece의 부분적인 스텝에만 어탠션을 적용하는 local approach를 제안한다. local approach는 source sentence의 window를 통한 부분적인 context에 선택적으로 집중할 수 있고, 해당 부분은 변화가 가능하다. context vector는 집중하는 윈두우 사이즈만큼의 $[p_{t} - D, p_{t} + D]$ 부분 내에서 계산 및 가중치가 계산되고, $D$는 경험적으로 선택된다. 우리는 해당 모델의 두 가지 사안을 고려하였다.
- Monotonic alignment : source sentence와 target sentence 간의 어순이 같다고 가정하여, $p_{t} = t$ 라고 단순하게 세팅한다.
- Predictive alignment : monotonic alignment 와 같이 단순하게 설정하는 것에서 넘어서, 학습을 통해 예측한다. $S$는 source sentence의 길이고, 뒤에 term은 sigmoid이기 때문에, $[S,0]$ 값을 지닌다. 또한, attention weights가 $p_{t}$를 중앙점으로 하는 gassian distribution을 따를 것을 가정하여, 아래와 같은 식을 도출한다.
Input-feeding approach

우리들의 approach에서, 어탠션 메카니즘은 독립적으로 만들어진다. 반면에 일반적인 기계 번역에서는 어떤 source words가 번역이 되었는지를 지속적으로 체크하면서 적용범위가 유지된다. 즉, 이전 스테이트의 정보가 새로운 alignment model에 적용되어야 한다는 것이다. $e_{ij}=a(s_{i-1}, h_j)$와 같이 말이다. 이런 부분을 고려해주기 위해서, 우리는 input-feeding approach를 적용해준다. 해당 접근법은 $x_{t+1}$라는 다음 시점의 input과 ${ \widetilde { h } }{ t }$를 (여기서 ${ \widetilde { h } }{ t }$는 이전 스테이트의 독립적으로 만들어진 attention model이다.)concat해서 넣어준다. 이를 통해서, 이전 스텝의 alignment model의 정보를 concat을 통해 삽입할 수 있고, 수평,수직적으로 보다 깊은 뉴럴 네트워크를 쌓을 수 있게 된다.
Training Details
- 문장의 길이가 토큰의 갯수가 50이 넘지 않는 것들로 필터링하였다.
- 4 레이어 LSTM을 사용하였다.
- hidden state의 차원 : 1000
- embedding vector의 차원 : 1000
- 파라미터는 [-0.1,0.1]로 초기화
- Loss function : Stochastic Gradient Descent
- Epoch : 5
- SGD의 learning rate 은 1로 시작해서, epoch가 1씩 커질 때마다 1/2 로 decay
- LSTM 에 0.2의 probability로 Dropout, Dropout 한 모델은 12의 epoch를 사용하였고, 8 epoch가 넘어갈 때부터 1/2 씩 learning rate을 decay
- local attention 에서 D는 10을 사용하였다.
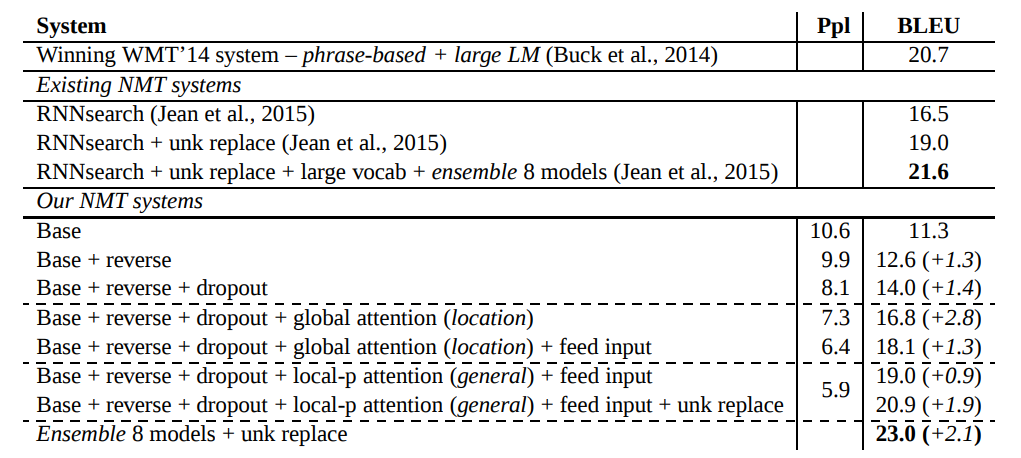
Experiment results
Conclusion
어탠션 메커니즘에서 global approach 와 local approach 라는 두 가지 방법론을 제안하였고, local attention model은 non-attention model보다 BLEU 점수에서 5.0의 우위를 차지하였다. 또한, 영어-독일어 번역 작업에서 8가지 모델을 앙상블한 방법론은 SOTA의 성능을 보였다.
Attention 논문에 이어서, 어탠션 메커니즘을 효율적으로 활용하는 구글에서 나온 논문 Neural Machine Effective Approaches to Attention-based Neural Machine Translation 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstact
어탠션 메카니즘은 source sentence의 특정 시퀀스에 집중시켜, 기계 번역의 성능을 향상시키는 데에 기여했다. 해당 논문은 효율적 어탠션 메카니즘을 두 가지 방식으로 제안 및 실험한다. 첫 번째는 global approach로, 모든 source sentence에 대해 어탠션을 적용한다. 두 번째로는 local approach로 source 단어들의 일부에 어탠션을 집중시킨다. local attention을 적용함에 따라, 어탠션이 적용되지 않은 방법보다 5.0 BLEU 만큼의 성능 향상이 있는 것을 보였다.
Introduction
기존의 RNN Encoder-Decoder 모델은 Sequence to Sequence의 기계학습을 가능케 만들었지만, 장거리 의존성을 잡아내기엔 무리가 있었다. 이어서 어탠션 메카니즘이 등장하였고, 자연어처리뿐만 아니라 많은 분야에서 해당 방법론이 사용되었다. 하지만, 이러한 어탠션 메카니즘을 어떻게 사용할 지에 대한 논의는 이뤄지지 않은 실정이다.
해당 논문에서 두 가지의 attention-based models 을 소개한다. source words에 대해 모두 어탠션을 적용하는 global approach와 한 번에 source words의 일부에 어탠션을 적용하는 local approach이다.
global approach는 2015년도의 Bahdanau 의 논문 형태와 유사하지만, 더욱 연산적으로 간단하다. local approach의 경우에는 hard attention 과 soft attention의 조합으로 나오며, 연산적으로 훨씬 간단하고 효율적이다.
Neural Machine Translation
인공신경망을 이용한 기계번역은 아래의 식을 최대화하는 방향으로 학습된다.
NMT에서 Encoder-Decoder 아키텍처를 쌓을 때, RNN 기반의 네트워크를 사용하는 것은 자연스러운 선택이였으며, 그동안 진행되오던 논문들은 Encoder가 Decoder에서 건네어 주는, source sentence에 대한 표상(representation)의 차이로 나뉘어졌다.
- Kalchbrenner and Blunsom (2013) 의 경우에는 decoder는 RNN 베이스를 사용하였고, Encoder에서 source sentence 표상을 CNN 모델로 진행하였다.
- Sutskever et al. (2014)dml 경우 multilayer_LSTM 의 hidden unit을 stack(concat) 사용하였다.
- Cho et al. (2014), Bahdanau et al. (2015), and Jean et al. (2015) 에서는 LSTM과 유사하지만, 연산의 간편성을 가지고 나온 GRU 모델을 아키텍처로 사용, 해당 모델의 hidden unit을 사용하였다.
위의 두 식을 순서대로 해석하면, 첫 번째는 Vanila RNN 의 update식을 의미한다. 두 번째는, Vanila RNN의 hidden units 이 어떻게 학습되는지에 관한 수식이다. $s$는 source sentence 의 word를 의미한다.
해당 연구에서는, Sutskever et al., 2014; Luong et al., 2015 의 연구에 따라서, LSTM을 여러 겹 쌓은 모델을 사용한다.
Attention-based Models
해당 연구에서 사용하는 Attention mechanism의 적용 방법은 global, local approach 모두 아래와 같은 형태로 동일하다.
위의 식을 차례로 설명하면, Encoder의 stacked LSTM의 가장 상단의 hidden state $h_{t}$와 context vector $c_{t}$를 concatenate한 후에, tanh 함수를 씌워준 형태이다. 즉, context vector와 hidden state를 쌓아준 후에, RNN 에 학습시켜 새로운 hidden units을 얻는 형태이다. 두 번째로는, 이렇게 update된 hidden unit에 따라, ouput의 분포를 반환하는 것을 의미한다.
Global Attention
Global attentional model의 아이디어는 인코더의 모든 hidden state들을 context vector를 만들 때 고려한다는 것이다. 이에 따라, context vector의 길이는 source sentence에 의존적이고, 가변 길이의 벡터가 된다.
$h_{t}$는 디코더의 hidden unit으로, 인코더에 있는 source words간의 attention energy를 기반으로 softmax를 취해주어, 계산해준다.
위와 같이 계산되는 score는 content-based 함수라고 불리며, 위와 같이 3 가지 선택사항이 존재한다..
기존의 논문들은 바로 위의 식과 같은 형태로 attention이 적용된 context vector를 만들었는데, 즉 attention weight가 도출되면 이를 context vector와 곱해 가중합을 취해주는 꼴이였다. 이를 local-based 함수라고 부른다.
우리들의 global approach 는 to Bahdanau et al., 2015 와 유사하지만, 몇 가지 다른 점들이 존재한다. 첫 번째로 이전 논문이 Encoder에서 Bi-directional LSTM 을 사용해, stacked hidden unit을 보냈지만, 우리는 Encoder Decoder모두 최상단에 있는 hidden unit만 사용한다. 두 번째로 우리들의 연산 경로가 더 간단하다는 것이다. 이전의 논문에서는 이전 시점의 hidden unit $h_{t-1}$에서 다음 시점 $h_{t}$를 제시하였지만, 해당 논문에서는 동일 시점의 target hidden state를 source hidden state 와 함께 concat해주고, context weights 를 적용해주기 때문이다. 마지막으로, 위에서 보였던, 3가지 방식을 우리는 모두 적용하였지만, 이전 논문은 3번째 방법만 제시하였다.
Local Attention
global approach는 source sentence의 모든 스텝에 어탠션 메커니즘을 적용하기 때문에, 긴 문장에 대해서 비효율적인 연산을 진행해야 한다는 단점이 있다. 이에 따라서, source sentnece의 부분적인 스텝에만 어탠션을 적용하는 local approach를 제안한다. local approach는 source sentence의 window를 통한 부분적인 context에 선택적으로 집중할 수 있고, 해당 부분은 변화가 가능하다. context vector는 집중하는 윈두우 사이즈만큼의 $[p_{t} - D, p_{t} + D]$ 부분 내에서 계산 및 가중치가 계산되고, $D$는 경험적으로 선택된다. 우리는 해당 모델의 두 가지 사안을 고려하였다.
- Monotonic alignment : source sentence와 target sentence 간의 어순이 같다고 가정하여, $p_{t} = t$ 라고 단순하게 세팅한다.
- Predictive alignment : monotonic alignment 와 같이 단순하게 설정하는 것에서 넘어서, 학습을 통해 예측한다. $S$는 source sentence의 길이고, 뒤에 term은 sigmoid이기 때문에, $[S,0]$ 값을 지닌다. 또한, attention weights가 $p_{t}$를 중앙점으로 하는 gassian distribution을 따를 것을 가정하여, 아래와 같은 식을 도출한다.
Input-feeding approach
우리들의 approach에서, 어탠션 메카니즘은 독립적으로 만들어진다. 반면에 일반적인 기계 번역에서는 어떤 source words가 번역이 되었는지를 지속적으로 체크하면서 적용범위가 유지된다. 즉, 이전 스테이트의 정보가 새로운 alignment model에 적용되어야 한다는 것이다. $e_{ij}=a(s_{i-1}, h_j)$와 같이 말이다. 이런 부분을 고려해주기 위해서, 우리는 input-feeding approach를 적용해준다. 해당 접근법은 $x_{t+1}$라는 다음 시점의 input과 ${ \widetilde { h } }{ t }$를 (여기서 ${ \widetilde { h } }{ t }$는 이전 스테이트의 독립적으로 만들어진 attention model이다.)concat해서 넣어준다. 이를 통해서, 이전 스텝의 alignment model의 정보를 concat을 통해 삽입할 수 있고, 수평,수직적으로 보다 깊은 뉴럴 네트워크를 쌓을 수 있게 된다.
Training Details
- 문장의 길이가 토큰의 갯수가 50이 넘지 않는 것들로 필터링하였다.
- 4 레이어 LSTM을 사용하였다.
- hidden state의 차원 : 1000
- embedding vector의 차원 : 1000
- 파라미터는 [-0.1,0.1]로 초기화
- Loss function : Stochastic Gradient Descent
- Epoch : 5
- SGD의 learning rate 은 1로 시작해서, epoch가 1씩 커질 때마다 1/2 로 decay
- LSTM 에 0.2의 probability로 Dropout, Dropout 한 모델은 12의 epoch를 사용하였고, 8 epoch가 넘어갈 때부터 1/2 씩 learning rate을 decay
- local attention 에서 D는 10을 사용하였다.
Experiment results
Conclusion
어탠션 메커니즘에서 global approach 와 local approach 라는 두 가지 방법론을 제안하였고, local attention model은 non-attention model보다 BLEU 점수에서 5.0의 우위를 차지하였다. 또한, 영어-독일어 번역 작업에서 8가지 모델을 앙상블한 방법론은 SOTA의 성능을 보였다.
Comments