
Learning Loss for Active Learning
03 Jun 2019 | Deep_Learning HS
Active Learning 을 딥러닝에 적용하는 효과적인 방법론에 대해 다루고 있는데요. 이번에는 2019년에 KAIST 에서 나온 논문 “Learning Loss for Active Learning” 에 대해 이야기해보려 합니다.
구현 코드는 최대한 빨리 업로드하도록 하겠습니다!!
해당 논문을 보다 쉽게 이해하기 위해서는 직전에 다룬 논문인 “Diverse Mini-batch Active Learning” 논문과 비교하면서 하면 좋을 것 같습니다. 해당 논문뿐만 아니라, 그동안 진행되오던 Active Learning 관련 방법론들은 학습시키는 모델이 어떠한 예측값을 뱉어내고, (e.x softmax, logit) 그에 따라, 정보량을 계산하여 쿼리할 인스턴스를 정하는 과정이였습니다. 하지만, 딥러닝에는 굉장히 다양한 task 가 존재하게 됩니다. 자연어처리 분야만 해도, 분류(classification), 언어 모델(language modeling) 등 다양한 목적을 가진 학습이 존재하고, 이에 따라, 불확실성과 같은 정보량을 계산하는 방법들이 달라지게 됩니다. 논문에서 드는 예시로는, 연산량이 굉장히 가벼운 것에 비해 훌륭한 성과를 보여주는 uncertainty sampling 의 경우,object detection, semantic segmentation, and human pose estimation 과 같이 작업의 종류가 달라질 수록, 이에 맞는 방법을 재정의해야 한다고 합니다. 즉, task-dependent 한 방법론이 된다는 것이죠. 이에 따라, 해당 논문은 task 에 크게 의존하지 않고(task-agnostic), 딥러닝 자체적 특징인 loss 를 통해 정보력있는 인스턴스를 찾아내는 방법론을 제시합니다. loss 를 통해 정보력을 정의하기 위해서는, 해당 배치에 대한 loss 를 예측해야 합니다. 이에 따라 해당 논문에서는 loss prediction module 이라는 것이 등장하는데요. 아래 그림을 통해 확인할 수 있습니다.

위의 사진을 보게 되면, (a) 에서 기존에 우리가 학습시키려는 Model 과 loss prediction module 이 딱 붙어서 존재하는 것을 볼 수 있습니다. 해당 그림이 말하려는 것은 함께 학습된다!(jointly trained) 라는 것을 나타냅니다. 아래의 사진인 (b) 에서 이야기하는 것은 unlabeled data 에서 학습시킨 두 개의 모델을 통해 예측한 loss 를 반환한 후에 가장 높은 $k$ 개의 데이터 인스턴스를 쿼리하는 것을 의미합니다.
그렇다면 이 loss prediction model 은 어떻게 구성되어 있으며, 어떻게 학습이 되는걸까요??
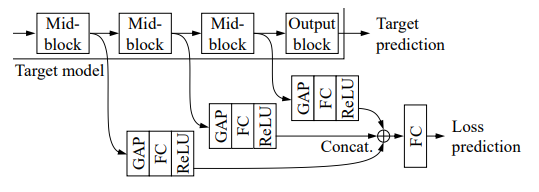
사진에서 Mid-block 이라고 쓰여져 있는 부분이 바로 기존 모델의 hidden state입니다. 즉, loss prediction module 의 input 은 hidden state $h$ 입니다. 그 이후, MLP 의 형태를 가진 상태로 logit 을 반환케하면 loss prediction module 이 됩니다. 이 중, GAP(Gloval Average Pooling) layer 는 각 층마다 다른 hidden state의 dimension 을 통일시켜주는 projection layer입니다. 이러한 모듈을 통해 $\hat{l}$ 이 예측됩니다.

본격적인 loss prediction module 학습 방법에 대해 이야기하기 전에, 학습의 전체 과정에 대해 훑고 지나가려 합니다. 메인 모델과 attach 된 loss prediction module은 iteration을 진행함에 따라, 실제 target label, loss를 비교하면서 학습이 진행되는 구조 아래에서 각각의 prediction을 반환합니다. 새로운 labeled data는 loss prediction의 상위 $k$로 쿼리합니다.
unlabeled data 에 대해서 저희는 loss 를 measure 할 수가 없기 때문에, 예측을 해야 하고, 옳게 예측하기 위해서는 기존의 지도 학습의 메커니즘과 같이 labeled dataset에서 학습을 해야 합니다. ${\theta_{target},\theta_{loss}}$ 를 통해 loss 를 계산하고, 이를 통해 back prop 을 해야 하는데, 더 나은 loss 예측을 위해서는 어떤 loss function 을 사용해야 할까요? 저자는 처음에 MSE 를 이야기합니다. $L_{target}(\hat{y},y) + \lambda*L_{loss}(\hat{l},l)$ 여기서 $L$ 을 MSE 로 정의했다는 것이죠. 하지만, loss의 크기는 학습 iteration 에 따라 작아지게 되어서 loss 정의에 scale 문제가 발생하기 때문에, 부적합하다는 결론이 나옵니다. 실제 실험 결과에도 부정적인 영향을 끼쳤다고 하네요.
이에 따라 나온 loss function 은 아래와 같습니다. 아래 식의 $p$는 partition 을 의미합니다.
조금 이야기로 풀어보면, 우선 training dataset 을 두개로 나눕니다.(이에 따라, 짝수가 되어야 합니다) 각각은 $i,j$가 됩니다. 같은 target loss 끼리 비교하고, 같은 prediction loss 끼리 비교해가면서, loss 를 정의하게 됨으로써, scale 에 대한 문제로써 벗어나게 되는 것이죠. 위의 식에서 epsilon 은 margin factor로써 1로 설정하고 실험을 했다고 합니다. 예로 들어, 실제 $i$ 번째 데이터에 대한 loss 가 $j$ 보다 크다고 했을 때, $l_{i} > l_{j}$ 우변의 첫번째 term은 -1 이 됩니다. loss값은 $i$의 prediction loss가 $j$보다 작아질 수록 커지게 됩니다. 즉, loss 가 작기 위해서는 target loss 의 관계와 최대한 유사한 값이 되어야 한다는 것이죠. 이러한 아이디어 아래에서 loss prediction module 이 학습됩니다.
제일 처음 나왔던 모델의 (a) 파트에서 보셨다시피, 메인 모델과 loss prediction module 은 jointly trained 상태이기 때문에, loss function 또한, 합쳐주어야 합니다. 함수는 아래와 같습니다.

Evaluation
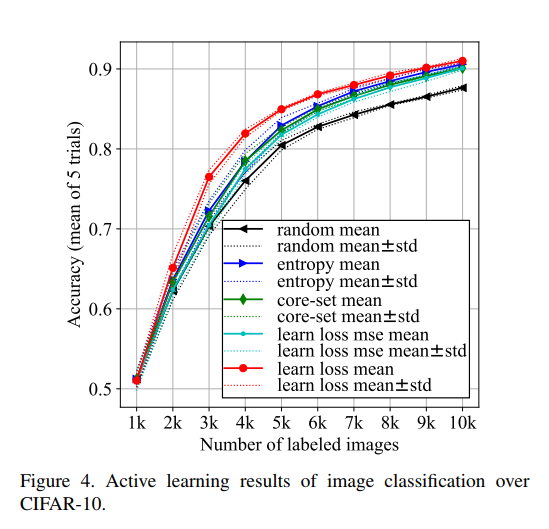
image classification 의 대표 데이터셋인 CIFAR-10 의 평과 결과입니다. 해당 논문의 방법론인 learn loss mean 이 상대적으로 우위에 있음을 확인하실 수 있습니다.
개인적으로 이전에 다뤘던 논문인 diverse mini-batch active learning 의 실험 결과가 좋지 않았던 터라, NLP 분야에 해당 방법론을 적용하면 어떠한 결과가 나올지 굉장히 기대가 됩니다. 피드백은 언제나 감사드리고 읽어주셔서 감사합니다!!
Active Learning 을 딥러닝에 적용하는 효과적인 방법론에 대해 다루고 있는데요. 이번에는 2019년에 KAIST 에서 나온 논문 “Learning Loss for Active Learning” 에 대해 이야기해보려 합니다.
구현 코드는 최대한 빨리 업로드하도록 하겠습니다!!
해당 논문을 보다 쉽게 이해하기 위해서는 직전에 다룬 논문인 “Diverse Mini-batch Active Learning” 논문과 비교하면서 하면 좋을 것 같습니다. 해당 논문뿐만 아니라, 그동안 진행되오던 Active Learning 관련 방법론들은 학습시키는 모델이 어떠한 예측값을 뱉어내고, (e.x softmax, logit) 그에 따라, 정보량을 계산하여 쿼리할 인스턴스를 정하는 과정이였습니다. 하지만, 딥러닝에는 굉장히 다양한 task 가 존재하게 됩니다. 자연어처리 분야만 해도, 분류(classification), 언어 모델(language modeling) 등 다양한 목적을 가진 학습이 존재하고, 이에 따라, 불확실성과 같은 정보량을 계산하는 방법들이 달라지게 됩니다. 논문에서 드는 예시로는, 연산량이 굉장히 가벼운 것에 비해 훌륭한 성과를 보여주는 uncertainty sampling 의 경우,object detection, semantic segmentation, and human pose estimation 과 같이 작업의 종류가 달라질 수록, 이에 맞는 방법을 재정의해야 한다고 합니다. 즉, task-dependent 한 방법론이 된다는 것이죠. 이에 따라, 해당 논문은 task 에 크게 의존하지 않고(task-agnostic), 딥러닝 자체적 특징인 loss 를 통해 정보력있는 인스턴스를 찾아내는 방법론을 제시합니다. loss 를 통해 정보력을 정의하기 위해서는, 해당 배치에 대한 loss 를 예측해야 합니다. 이에 따라 해당 논문에서는 loss prediction module 이라는 것이 등장하는데요. 아래 그림을 통해 확인할 수 있습니다.
위의 사진을 보게 되면, (a) 에서 기존에 우리가 학습시키려는 Model 과 loss prediction module 이 딱 붙어서 존재하는 것을 볼 수 있습니다. 해당 그림이 말하려는 것은 함께 학습된다!(jointly trained) 라는 것을 나타냅니다. 아래의 사진인 (b) 에서 이야기하는 것은 unlabeled data 에서 학습시킨 두 개의 모델을 통해 예측한 loss 를 반환한 후에 가장 높은 $k$ 개의 데이터 인스턴스를 쿼리하는 것을 의미합니다.
그렇다면 이 loss prediction model 은 어떻게 구성되어 있으며, 어떻게 학습이 되는걸까요??
사진에서 Mid-block 이라고 쓰여져 있는 부분이 바로 기존 모델의 hidden state입니다. 즉, loss prediction module 의 input 은 hidden state $h$ 입니다. 그 이후, MLP 의 형태를 가진 상태로 logit 을 반환케하면 loss prediction module 이 됩니다. 이 중, GAP(Gloval Average Pooling) layer 는 각 층마다 다른 hidden state의 dimension 을 통일시켜주는 projection layer입니다. 이러한 모듈을 통해 $\hat{l}$ 이 예측됩니다.
본격적인 loss prediction module 학습 방법에 대해 이야기하기 전에, 학습의 전체 과정에 대해 훑고 지나가려 합니다. 메인 모델과 attach 된 loss prediction module은 iteration을 진행함에 따라, 실제 target label, loss를 비교하면서 학습이 진행되는 구조 아래에서 각각의 prediction을 반환합니다. 새로운 labeled data는 loss prediction의 상위 $k$로 쿼리합니다.
unlabeled data 에 대해서 저희는 loss 를 measure 할 수가 없기 때문에, 예측을 해야 하고, 옳게 예측하기 위해서는 기존의 지도 학습의 메커니즘과 같이 labeled dataset에서 학습을 해야 합니다. ${\theta_{target},\theta_{loss}}$ 를 통해 loss 를 계산하고, 이를 통해 back prop 을 해야 하는데, 더 나은 loss 예측을 위해서는 어떤 loss function 을 사용해야 할까요? 저자는 처음에 MSE 를 이야기합니다. $L_{target}(\hat{y},y) + \lambda*L_{loss}(\hat{l},l)$ 여기서 $L$ 을 MSE 로 정의했다는 것이죠. 하지만, loss의 크기는 학습 iteration 에 따라 작아지게 되어서 loss 정의에 scale 문제가 발생하기 때문에, 부적합하다는 결론이 나옵니다. 실제 실험 결과에도 부정적인 영향을 끼쳤다고 하네요.
이에 따라 나온 loss function 은 아래와 같습니다. 아래 식의 $p$는 partition 을 의미합니다.
조금 이야기로 풀어보면, 우선 training dataset 을 두개로 나눕니다.(이에 따라, 짝수가 되어야 합니다) 각각은 $i,j$가 됩니다. 같은 target loss 끼리 비교하고, 같은 prediction loss 끼리 비교해가면서, loss 를 정의하게 됨으로써, scale 에 대한 문제로써 벗어나게 되는 것이죠. 위의 식에서 epsilon 은 margin factor로써 1로 설정하고 실험을 했다고 합니다. 예로 들어, 실제 $i$ 번째 데이터에 대한 loss 가 $j$ 보다 크다고 했을 때, $l_{i} > l_{j}$ 우변의 첫번째 term은 -1 이 됩니다. loss값은 $i$의 prediction loss가 $j$보다 작아질 수록 커지게 됩니다. 즉, loss 가 작기 위해서는 target loss 의 관계와 최대한 유사한 값이 되어야 한다는 것이죠. 이러한 아이디어 아래에서 loss prediction module 이 학습됩니다.
제일 처음 나왔던 모델의 (a) 파트에서 보셨다시피, 메인 모델과 loss prediction module 은 jointly trained 상태이기 때문에, loss function 또한, 합쳐주어야 합니다. 함수는 아래와 같습니다.
Evaluation
image classification 의 대표 데이터셋인 CIFAR-10 의 평과 결과입니다. 해당 논문의 방법론인 learn loss mean 이 상대적으로 우위에 있음을 확인하실 수 있습니다.
개인적으로 이전에 다뤘던 논문인 diverse mini-batch active learning 의 실험 결과가 좋지 않았던 터라, NLP 분야에 해당 방법론을 적용하면 어떠한 결과가 나올지 굉장히 기대가 됩니다. 피드백은 언제나 감사드리고 읽어주셔서 감사합니다!!
Comments