
Sequence to Sequence Learning with Neural Networks
06 Apr 2019 | NLP_paper HS
조경현 교수님의 RNN Seq2Seq 논문에 이어 구글에서 나온 논문 Sequence to Sequence Learning with Neural Networks 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstract
우리는 일반적인 end-to-end approach 를 사용해서 시퀀스를 학습한다. RNN Encoder-Decoder 모델을 학습하는데 있어서, Multi-layer LSTM 을 사용할 것이다. 또한, 우리는 source sentence 의 순서를 역으로(reversing) 만드는 것이 긴 문장에 대해서 장거리 의존성을 해결하고, 성능 향상에 도움을 준다는 것을 확인했다.
Introduction
DNN(Deep Neural Network) 모델은 이미지 인식과 음성 인식과 같은 어려운 문제들을 많이 해결해오면서 각광을 받고 있지만, input과 output 데이터의 차원(dimension)이 고정되어 있어야 한다는 제약조건이 따른다. 이에 따라서, RNN Encoder-Decoder 모델을 사용하며, 해당 모델은 Encoder에서 가변 길이의 시퀀스 데이터를 고정된 차원의 벡터로 만들고, Decoder 단계에서는 Encoder에서 나온 고정된 차원의 벡터를 다시 가변 길이의 시퀀스 형태로 되돌려 놓는 형태를 의미한다.
해당 논문에서는 DNN의 아키텍처를 Long Short-Term Memory(LSTM)을 사용할 것이며, 이를 통해 sequence to sequence 문제를 해결하고자 한다. LSTM 을 사용할 때에는 5개의 layer를 사용해 보다 깊게 층을 구성할 것이며, simple left-to-right beam-search decoder를 사용한다.
LSTM에 더해서, 우리는 장거리 의존성 문제를 해결하기 위해서,source sentence 즉, 번역하고자 하는 문장을 거꾸로 Encoder에 집어 넣는 과정을 진행하였다. 이러한 간단한 트릭은 해당 연구의 기술적 기여도 중 하나이다.

The model
위의 이미지에서 보이는 바와 같이, Encoder Decoder를 적용하였고, 각각의 아키텍처는 LSTM을 사용하였다. LSTM으 미고표는 조건부 확률
을 예측하려는 것이다. 또한, source sentence, target sentence 각각 문장의 끝에 End of Sentence 를 의미하는 토큰이 있는 것을 확인할 수 있다. 이는 모델이 문장의 길이를 파악하고, 이에 따른 분포를 정의하게 해주기 위함이다. (이미지 처리에서 이미지의 모서리 부분에 토큰을 처리해줌으로써, 이미지의 크기와 모서리를 정의하는 것과 같은 맥락입니다.)
또한, 위에서 언급했던 것과 마찬가지로, 4개의 층을 가지는 deep 한 LSTM 아키텍처를 사용하였다. 마지막으로는 input sentence 즉, source sentence의 순서를 역순으로 배치하였다. 예로 들어서, 기존에 $a,b,c,eos$ 였다면 $c,b,a,eos$가 되는 것이다.
Decoding and Rescoring
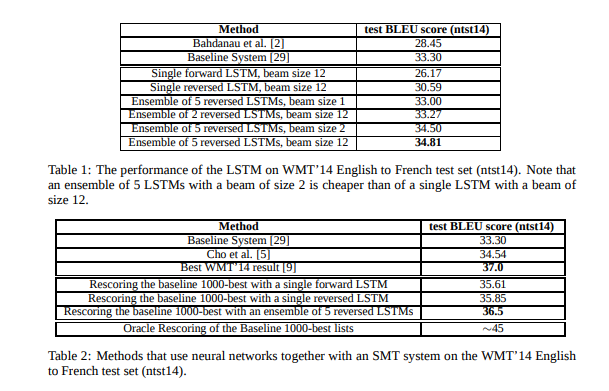
간단한 left-to-right beam search decoder를 사용하였다. 빔 사이즈가 1일 때도(greedy search) 훌륭한 결과를 보였고, 사이즈가 커질 수록 높은 성능을 보여주었다.
Reversing the Source Sentences
(해당 논문의 핵심적인 부분이 아닐까 싶습니다.)
우리는 LSTM 모델이 인풋 시퀀스 데이터의 순서가 역순일 때, 학습이 훨씬 더 잘된다는 사실을 발견하였다. 그 이유에 대한 완벽한 설명은 하지 않았지만, 장거리 의존성에 따른 문제를 해결할 수 있어서라고 믿는다. 일반적으로 source data와 target data를 pair로 묶어서 학습을 시키게 되는데, 이 과정에서 minimal time lag이라는 문제가 발생한다. 즉, source data의 시작점과 target data의 시작점이 너무 멀다는 것이다. 하지만 source sentence의 순서를 거꾸로 넣어줌으로써, minimal time lag의 효과가 매우 절감되는 것을 확인할 수 있었다.
처음에는, source sentence의 순서를 거꾸로 넣어준다는 것이, 예측하는 새로운 문장의 처음에는 잘 맞아떨어지지만, 뒤쪽 문장 형성에는 문제가 생길 것이라고 생각했다. 하지만 LSTM 모델은 전체적으로 더 나은 성능을 보여주었다.
Training details
- LSTM 의 파라미터를 [-0.08,0.08]의 유니폼 분포로 초기화하였다.
- SGD loss function을 사용, 0.7 learning rate으로 시작하여서, 5 에포크마다 절반으로 decay 시켜주었다.
- 7.5 epochs 사용
- 128 Batch size 사용
- gradient normalization [10,25] 적용
- 학습을 빠르게 하기 위해서, source sentence 간 길이를 맞춰주어서, 학습 속도를 2배 빠르게 하였다.
Model analysis
해당 모델은 source sentence를 고정된 벡터차원으로 변환하기 때문에, 단어 표상을 학습할 수 있다.

Conclusion
LSTM을 deep하게 쌓는 것과 source sequence data의 순서를 역순(reverse in order)으로 학습시키는 것이 성능향상에 기여하였다.
조경현 교수님의 RNN Seq2Seq 논문에 이어 구글에서 나온 논문 Sequence to Sequence Learning with Neural Networks 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstract
우리는 일반적인 end-to-end approach 를 사용해서 시퀀스를 학습한다. RNN Encoder-Decoder 모델을 학습하는데 있어서, Multi-layer LSTM 을 사용할 것이다. 또한, 우리는 source sentence 의 순서를 역으로(reversing) 만드는 것이 긴 문장에 대해서 장거리 의존성을 해결하고, 성능 향상에 도움을 준다는 것을 확인했다.
Introduction
DNN(Deep Neural Network) 모델은 이미지 인식과 음성 인식과 같은 어려운 문제들을 많이 해결해오면서 각광을 받고 있지만, input과 output 데이터의 차원(dimension)이 고정되어 있어야 한다는 제약조건이 따른다. 이에 따라서, RNN Encoder-Decoder 모델을 사용하며, 해당 모델은 Encoder에서 가변 길이의 시퀀스 데이터를 고정된 차원의 벡터로 만들고, Decoder 단계에서는 Encoder에서 나온 고정된 차원의 벡터를 다시 가변 길이의 시퀀스 형태로 되돌려 놓는 형태를 의미한다.
해당 논문에서는 DNN의 아키텍처를 Long Short-Term Memory(LSTM)을 사용할 것이며, 이를 통해 sequence to sequence 문제를 해결하고자 한다. LSTM 을 사용할 때에는 5개의 layer를 사용해 보다 깊게 층을 구성할 것이며, simple left-to-right beam-search decoder를 사용한다.
LSTM에 더해서, 우리는 장거리 의존성 문제를 해결하기 위해서,source sentence 즉, 번역하고자 하는 문장을 거꾸로 Encoder에 집어 넣는 과정을 진행하였다. 이러한 간단한 트릭은 해당 연구의 기술적 기여도 중 하나이다.
The model
위의 이미지에서 보이는 바와 같이, Encoder Decoder를 적용하였고, 각각의 아키텍처는 LSTM을 사용하였다. LSTM으 미고표는 조건부 확률
을 예측하려는 것이다. 또한, source sentence, target sentence 각각 문장의 끝에 End of Sentence 를 의미하는
또한, 위에서 언급했던 것과 마찬가지로, 4개의 층을 가지는 deep 한 LSTM 아키텍처를 사용하였다. 마지막으로는 input sentence 즉, source sentence의 순서를 역순으로 배치하였다. 예로 들어서, 기존에 $a,b,c,eos$ 였다면 $c,b,a,eos$가 되는 것이다.
Decoding and Rescoring
간단한 left-to-right beam search decoder를 사용하였다. 빔 사이즈가 1일 때도(greedy search) 훌륭한 결과를 보였고, 사이즈가 커질 수록 높은 성능을 보여주었다.
Reversing the Source Sentences
(해당 논문의 핵심적인 부분이 아닐까 싶습니다.) 우리는 LSTM 모델이 인풋 시퀀스 데이터의 순서가 역순일 때, 학습이 훨씬 더 잘된다는 사실을 발견하였다. 그 이유에 대한 완벽한 설명은 하지 않았지만, 장거리 의존성에 따른 문제를 해결할 수 있어서라고 믿는다. 일반적으로 source data와 target data를 pair로 묶어서 학습을 시키게 되는데, 이 과정에서 minimal time lag이라는 문제가 발생한다. 즉, source data의 시작점과 target data의 시작점이 너무 멀다는 것이다. 하지만 source sentence의 순서를 거꾸로 넣어줌으로써, minimal time lag의 효과가 매우 절감되는 것을 확인할 수 있었다.
처음에는, source sentence의 순서를 거꾸로 넣어준다는 것이, 예측하는 새로운 문장의 처음에는 잘 맞아떨어지지만, 뒤쪽 문장 형성에는 문제가 생길 것이라고 생각했다. 하지만 LSTM 모델은 전체적으로 더 나은 성능을 보여주었다.
Training details
- LSTM 의 파라미터를 [-0.08,0.08]의 유니폼 분포로 초기화하였다.
- SGD loss function을 사용, 0.7 learning rate으로 시작하여서, 5 에포크마다 절반으로 decay 시켜주었다.
- 7.5 epochs 사용
- 128 Batch size 사용
- gradient normalization [10,25] 적용
- 학습을 빠르게 하기 위해서, source sentence 간 길이를 맞춰주어서, 학습 속도를 2배 빠르게 하였다.
Model analysis
해당 모델은 source sentence를 고정된 벡터차원으로 변환하기 때문에, 단어 표상을 학습할 수 있다.
Conclusion
LSTM을 deep하게 쌓는 것과 source sequence data의 순서를 역순(reverse in order)으로 학습시키는 것이 성능향상에 기여하였다.
Comments