
Deep contextualized word representations
15 Apr 2019 | NLP_paper HS
word2vec, Glove, Fasttext에 이어 단어 임베딩의 새로운 방법론을 제시한 ELMO의 탄생작, “Deep contextualized word representations” 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstract
해당 논문에서 우리는 단어의 복잡한 특성(문법과 의미론적)과 문맥에 따라 언어적 의미가 달라지는 것을 사용한 새로운 타입의 모델인 “깊은 문맥화된 단어 표상법”을 소개한다. 우리의 단어 벡터는 많은 양의 텍스트 데이터가 깊은 양방향 언어 모델(biLM)으로 부터 학습됨으로써 나온다. 또한, 이렇게 학습된 단어 벡터가 기존의 모델에 쉽게 접목되고 SOTA 의 성능을 보임을 증명한다.
Introduction
우리의 임베딩 벡터는 기존의 단어 벡터와 다른 점이 존재하는데, 바로 모든 인풋 데이터들을 반영해서 표상(representation)이 주어진다는 것이다. 우리는 양방향 LSTM을 통해 단어 벡터를 유도해낸다. 이러한 이유에 따라서 우리는 “언어 모델을 통한 임베딩” 즉, ELMo(Embeddings from Lanuage Mdels)라고 칭한다. 이전의 문맥적 단어 벡터를 만드려는 접근과는 달리s(Peters et al., 2017; McCann et al., 2017) EMLo 표상은 깊은 언어 모델의 모든 내부 층들을 함수로 삼는다. 더 구체적으로는, 모든 인풋 시퀀스의 벡터들을 쌓아올린 상태에서 선형 결합을 한 것을 학습한다는 것이다. 이는 단순히 LSTM의 제일 윗층의 것만 사용했을 때도 성능을 개선시킨다.
내부 층들을 결합시키는 과정은 풍부한 단어 표상이 가능하게끔 만들어준다. 내부 평가에서, 우리는 깊은 LSTM이 문맥에 의존하는 단어의 의미를 잘 포착하고 있는 것을 확인했다. 추가적인 연구에서는 ELMo 표상법이 실제로도 잘 작동한다는 것을 확인하였다. (NLP의 여섯 가지 대표 문제에서 최대 20%의 성능 향상의 효과를 보였다.)
ELMo : Embeddings from Language Models
다른 단어 표상법과는 달리, ELMo는 전체 인풋 문장을 받아드린다.(functions of the entire input sentence) ELMo는 2 layer bi_LSTM을 문자 CNN(CharCNN)으로 받고(3.1 section), 내부 층들의 선형 함수를 거쳐서(3.2 section), 준-지도 학습이 가능하게끔 해준다(3.4 section), 그리고 여러 NLP task에 접목됨을 보인다.
- 3.1 Section Bidirectional language models
Bidirectional LSTM을 적용합니다. 마지막에는 양방향의 로그 확률을 더해서 이를 최대화하는 MLE를 진행합니다.

- 3.2 ELMo
ELMo는 biLM에 있는 중간 레이어의 표상들을(intermediate layer representations) 의 결합이다.
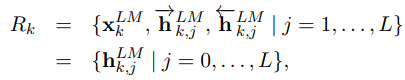
위의 그림에서 $t_{k}$는 각각의 토큰을 의미하고, $j=1,…,L$은 레이어를 의미합니다.
ELMo의 가장 간단한 경우에는 히든 레이어의 가장 상위 층만 사용하지만, 좀 더 일반적으로, 우리는 모든 biLM 레이어의 값들을 고려해준다.
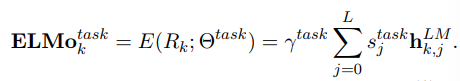
$s_{task}$는 softmax-normalized 가중치이고, $r_{task}$는 전체 ELMo 벡터의 스케일을 조절하는 파라미터이다. $r$은 최적화 프로세스에서 중요한 역할을 한다.
biLM에서 각각의 레이어들의 활성화 값들은 다른 분포를 가지고 있다고 간주하기 때문에, 어쩔 때는, 레이어 노멀라이제이션(layer normalization)을 해주는 것이 도움이 될 때가 있다. (여기서 biLM과 bi-LSTM의 차이점이 나옵니다. bi-LSTM을 2-layer로 구성했을 경우에는 두 개의 레이어가 동시에 학습되지만, biLM의 경우 각각의 레이어가 스택의 형태로 합쳐져 있긴 하지만, 각 레이어가 별개로 학습 및 최적화가 됩니다.)
- 3.3 Using biLMs for supervised NLP tasks
biLM 모델을 실행시키고, 각 단어의 모든 레이어 표상들을 기록하면 된다. 그리고 이러한 표상들을 선형 함수에 넣으면 된다. 첫번째로 biLM을 제외한 지도 학습 모델의 가장 낮은(첫 번째로 거치게 되는) 레이어를 생각해보자. 대부분이 같은 형태를 띄고 있을 것이며, 그 부분에 우리의 ELMo를 추가해준다.
기본적인 아키텍처에서는 문맥에 독립적인 단어 또는 문자 벡터(character-level vector) $x_{k}$를 미리 학습된 임베딩 벡터에 넣어서 RNN 또는 CNN 모델을 사용해 문맥에 의존적으로 만든다.
지도 학습에 ELMo를 추가한다면, 학습한 ELMo 벡터의 가중치를 고정시킨 상태에서 input sequence에 concat 하는 $[x_{k};ELMo_{k}]$의 형태로 만든다. 또는 input sequence가 아닌, hidden states에 concat하는 $[h_{k};ELMo_{k}]$의 형태도 성능 개선에 효과가 있었음을 확인했다.
결과적으로, ELMo의 dropout을 추가한 것과 L2 regularization한 ELMo가 효과적이였음을 확인하였다.
Pre-trained bidirectional language model architecture
미리 학습된 biLMs 모델은 Jozefowicz (2016) 과 Kim (2015) 에서 나왔던 모델과 유사하다. 하지만, 양방향을 고려하고 모든 LSTM 레이어를 고려했다는 점이 다르다.
전체적인 모델의 input을 character-based input으로 유지하면서, perplexity를 모델의 사이즈와 연산 비용을 함께 고려하여 CNN-BIG-LSTM 모델을 사용한다.(CharCNN + 2-layer-LSTM + projection layer) (Jozefowicz (2016))
최종적인 모델은 레이어가 2이고 $L = 2$ LSTM의 레이어 사이에 [4092,512]의 projection layer를 사용하며,(40924092의 연산을 가운데에 [4092,512]의 projection layer를 넣어서 4092512*2 로 파라미터의 갯수를 줄여주게 됩니다.) character based CNN에서는 2개의 highway layer와 2048개의 필터를 사용하고, projection 으로 (fully connected layer를 의미하는 것으로 해석됩니다.) 차원을 512로 줄여준다.
이에 따라, 기존의 임베딩 모델의 층은 고정된 어휘 토큰들에 대해서 오직 하나의 층을 가지는 것에 반해 우리의 모델은 총 3개의 레이어가 된다.(char-based CNN + biLMs)
Evaluation
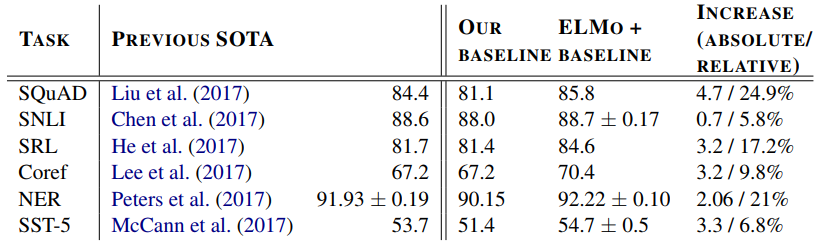
word2vec, Glove, Fasttext에 이어 단어 임베딩의 새로운 방법론을 제시한 ELMO의 탄생작, “Deep contextualized word representations” 논문에 대해 다뤄보도록 하겠습니다. 모든 내용과 이미지는 해당 논문을 참고합니다.
구현 코드는 깃헙 사이트를 참고해주시면 감사하겠습니다.
Abstract
해당 논문에서 우리는 단어의 복잡한 특성(문법과 의미론적)과 문맥에 따라 언어적 의미가 달라지는 것을 사용한 새로운 타입의 모델인 “깊은 문맥화된 단어 표상법”을 소개한다. 우리의 단어 벡터는 많은 양의 텍스트 데이터가 깊은 양방향 언어 모델(biLM)으로 부터 학습됨으로써 나온다. 또한, 이렇게 학습된 단어 벡터가 기존의 모델에 쉽게 접목되고 SOTA 의 성능을 보임을 증명한다.
Introduction
우리의 임베딩 벡터는 기존의 단어 벡터와 다른 점이 존재하는데, 바로 모든 인풋 데이터들을 반영해서 표상(representation)이 주어진다는 것이다. 우리는 양방향 LSTM을 통해 단어 벡터를 유도해낸다. 이러한 이유에 따라서 우리는 “언어 모델을 통한 임베딩” 즉, ELMo(Embeddings from Lanuage Mdels)라고 칭한다. 이전의 문맥적 단어 벡터를 만드려는 접근과는 달리s(Peters et al., 2017; McCann et al., 2017) EMLo 표상은 깊은 언어 모델의 모든 내부 층들을 함수로 삼는다. 더 구체적으로는, 모든 인풋 시퀀스의 벡터들을 쌓아올린 상태에서 선형 결합을 한 것을 학습한다는 것이다. 이는 단순히 LSTM의 제일 윗층의 것만 사용했을 때도 성능을 개선시킨다.
내부 층들을 결합시키는 과정은 풍부한 단어 표상이 가능하게끔 만들어준다. 내부 평가에서, 우리는 깊은 LSTM이 문맥에 의존하는 단어의 의미를 잘 포착하고 있는 것을 확인했다. 추가적인 연구에서는 ELMo 표상법이 실제로도 잘 작동한다는 것을 확인하였다. (NLP의 여섯 가지 대표 문제에서 최대 20%의 성능 향상의 효과를 보였다.)
ELMo : Embeddings from Language Models
다른 단어 표상법과는 달리, ELMo는 전체 인풋 문장을 받아드린다.(functions of the entire input sentence) ELMo는 2 layer bi_LSTM을 문자 CNN(CharCNN)으로 받고(3.1 section), 내부 층들의 선형 함수를 거쳐서(3.2 section), 준-지도 학습이 가능하게끔 해준다(3.4 section), 그리고 여러 NLP task에 접목됨을 보인다.
- 3.1 Section Bidirectional language models
Bidirectional LSTM을 적용합니다. 마지막에는 양방향의 로그 확률을 더해서 이를 최대화하는 MLE를 진행합니다.
- 3.2 ELMo
ELMo는 biLM에 있는 중간 레이어의 표상들을(intermediate layer representations) 의 결합이다.
위의 그림에서 $t_{k}$는 각각의 토큰을 의미하고, $j=1,…,L$은 레이어를 의미합니다.
ELMo의 가장 간단한 경우에는 히든 레이어의 가장 상위 층만 사용하지만, 좀 더 일반적으로, 우리는 모든 biLM 레이어의 값들을 고려해준다.
$s_{task}$는 softmax-normalized 가중치이고, $r_{task}$는 전체 ELMo 벡터의 스케일을 조절하는 파라미터이다. $r$은 최적화 프로세스에서 중요한 역할을 한다.
biLM에서 각각의 레이어들의 활성화 값들은 다른 분포를 가지고 있다고 간주하기 때문에, 어쩔 때는, 레이어 노멀라이제이션(layer normalization)을 해주는 것이 도움이 될 때가 있다. (여기서 biLM과 bi-LSTM의 차이점이 나옵니다. bi-LSTM을 2-layer로 구성했을 경우에는 두 개의 레이어가 동시에 학습되지만, biLM의 경우 각각의 레이어가 스택의 형태로 합쳐져 있긴 하지만, 각 레이어가 별개로 학습 및 최적화가 됩니다.)
- 3.3 Using biLMs for supervised NLP tasks
biLM 모델을 실행시키고, 각 단어의 모든 레이어 표상들을 기록하면 된다. 그리고 이러한 표상들을 선형 함수에 넣으면 된다. 첫번째로 biLM을 제외한 지도 학습 모델의 가장 낮은(첫 번째로 거치게 되는) 레이어를 생각해보자. 대부분이 같은 형태를 띄고 있을 것이며, 그 부분에 우리의 ELMo를 추가해준다.
기본적인 아키텍처에서는 문맥에 독립적인 단어 또는 문자 벡터(character-level vector) $x_{k}$를 미리 학습된 임베딩 벡터에 넣어서 RNN 또는 CNN 모델을 사용해 문맥에 의존적으로 만든다.
지도 학습에 ELMo를 추가한다면, 학습한 ELMo 벡터의 가중치를 고정시킨 상태에서 input sequence에 concat 하는 $[x_{k};ELMo_{k}]$의 형태로 만든다. 또는 input sequence가 아닌, hidden states에 concat하는 $[h_{k};ELMo_{k}]$의 형태도 성능 개선에 효과가 있었음을 확인했다.
결과적으로, ELMo의 dropout을 추가한 것과 L2 regularization한 ELMo가 효과적이였음을 확인하였다.
Pre-trained bidirectional language model architecture
미리 학습된 biLMs 모델은 Jozefowicz (2016) 과 Kim (2015) 에서 나왔던 모델과 유사하다. 하지만, 양방향을 고려하고 모든 LSTM 레이어를 고려했다는 점이 다르다.
전체적인 모델의 input을 character-based input으로 유지하면서, perplexity를 모델의 사이즈와 연산 비용을 함께 고려하여 CNN-BIG-LSTM 모델을 사용한다.(CharCNN + 2-layer-LSTM + projection layer) (Jozefowicz (2016))
최종적인 모델은 레이어가 2이고 $L = 2$ LSTM의 레이어 사이에 [4092,512]의 projection layer를 사용하며,(40924092의 연산을 가운데에 [4092,512]의 projection layer를 넣어서 4092512*2 로 파라미터의 갯수를 줄여주게 됩니다.) character based CNN에서는 2개의 highway layer와 2048개의 필터를 사용하고, projection 으로 (fully connected layer를 의미하는 것으로 해석됩니다.) 차원을 512로 줄여준다.
이에 따라, 기존의 임베딩 모델의 층은 고정된 어휘 토큰들에 대해서 오직 하나의 층을 가지는 것에 반해 우리의 모델은 총 3개의 레이어가 된다.(char-based CNN + biLMs)
Evaluation
Comments